自定义仪表盘
自定义仪表盘是 Cloud Insight 的核心功能。在仪表盘的章节中,我们提到 Cloud Insight 仪表盘的核心逻辑是:

即 Cloud Insight 通过 3 个步骤达到操作系统、数据库、中间件,以及未来通过 Developer API 对接进来的所有 Metric 进行处理:
- Cloud Insight Agent 采集并处理 Metric;
- 在平台服务仪表盘和自定义仪表盘中,提供 Metric 聚合、分组、统计运算、基本数学运算等操作;
- 针对操作的结果,提供曲线图、柱状图等多样化的展现形式。
由于 Cloud Insight 自定义仪表盘的操作,有一些些复杂,所以我们拆开来说:
- 基本操作
- Metric 查询
- 参数使用
- 功能操作
基本操作
平台服务仪表盘,能够提供用户只读的权限;而自定义仪表盘提供增删改的权限。所有的基本操作包括:
- 创建仪表盘
- 删除仪表盘
- 编辑仪表盘
- 创建副本
而使用仪表盘包括以下的页面:
- 仪表盘列表
- 仪表盘搜索
- 收藏仪表盘
创建和删除仪表盘
用户可通过「添加仪表盘」按钮,或者从其他仪表盘「创建副本」来创建新的自定义仪表盘。
添加仪表盘
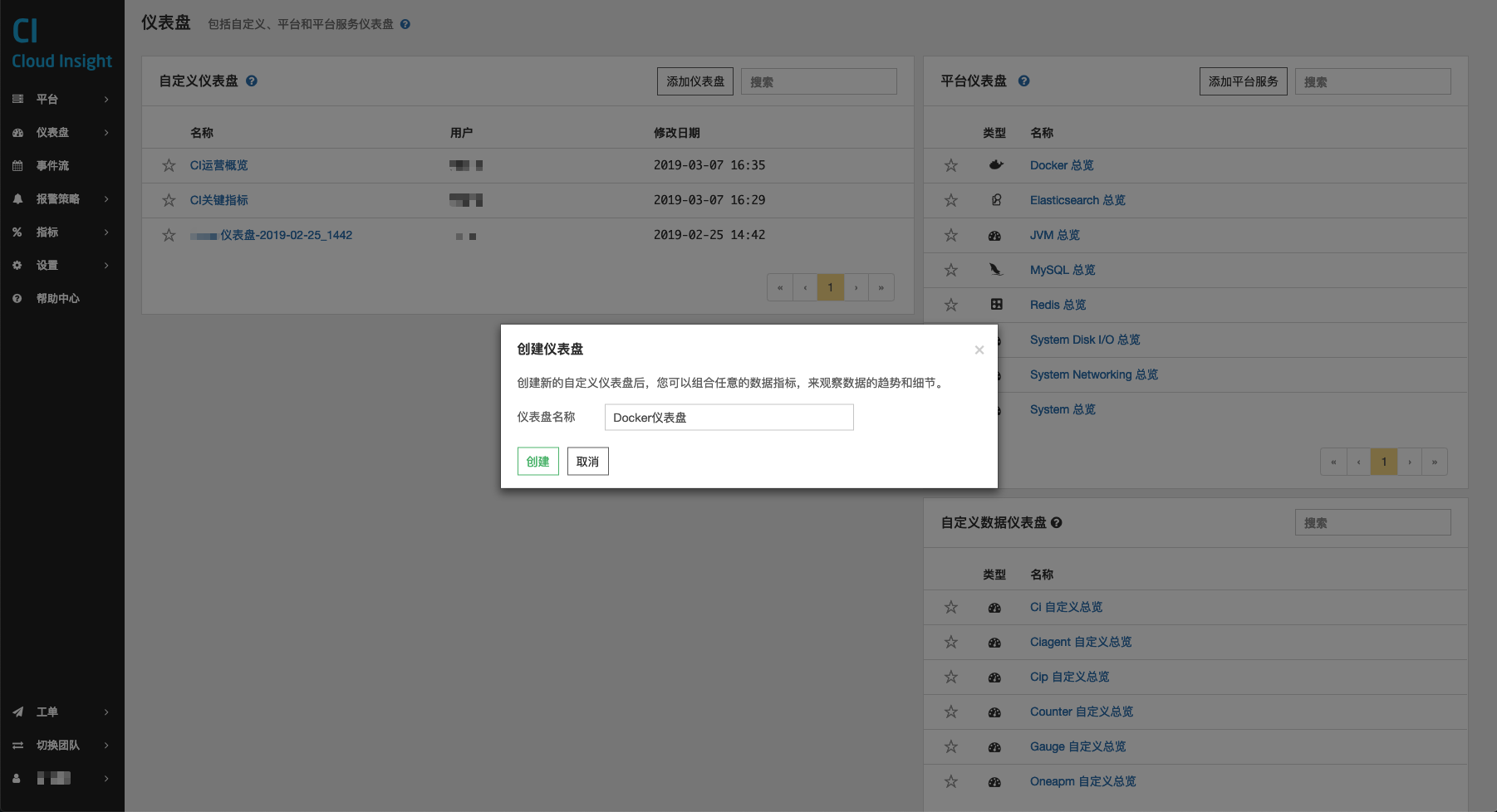
输入仪表盘名称,即创建了一个新的自定义仪表盘。
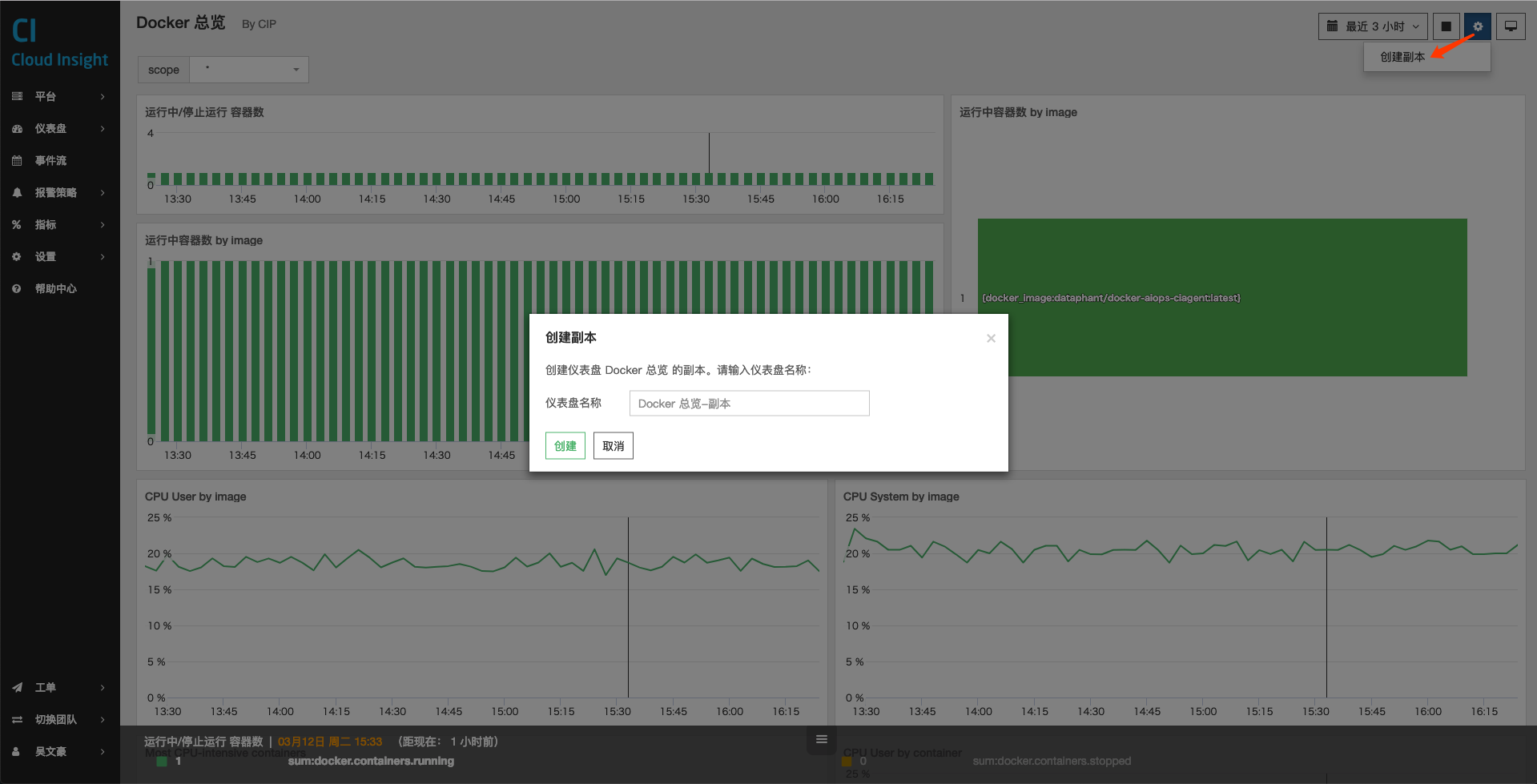
创建副本
由于平台服务仪表盘,针对所有用户都只有只读权限。如果想编辑平台服务仪表盘,需要:
- 创建该平台服务仪表盘的副本
- 该副本会变为一个新的自定义仪表盘
- 编辑该自定义仪表盘
删除仪表盘
删除仪表盘和创建副本,都隐藏在仪表盘页面右上角的设置按钮中。
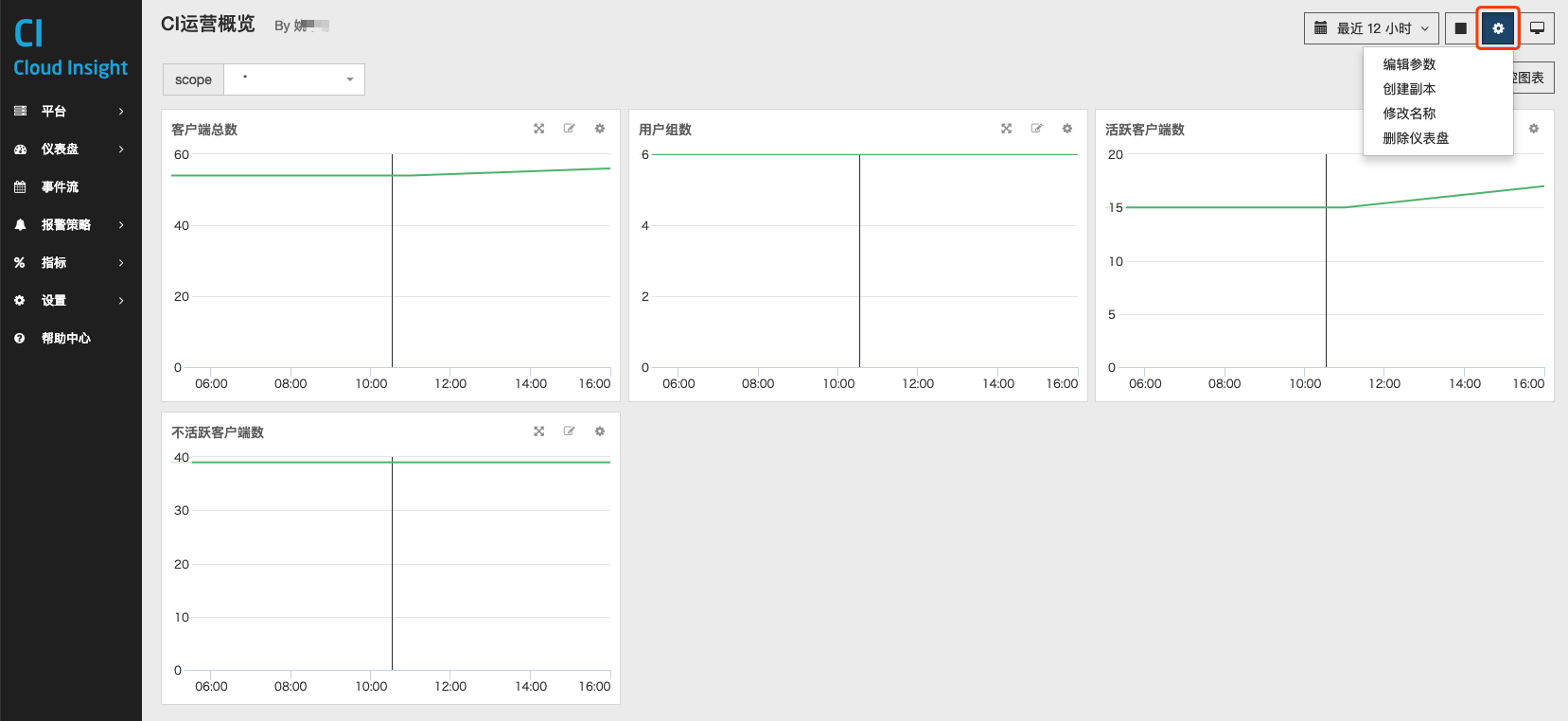
编辑仪表盘
编辑仪表盘包括:
- 修改仪表盘的名称
- 添加监控图表
仪表盘是全团队可见的,但是仪表盘的最初创建者,会记录在仪表盘列表中。而团队成员都拥有,对自定义仪表盘的读写权限。
针对以下的「添加监控图表」,由于逻辑复杂,所以我们留到下一个小节,做介绍。
Metric 查询
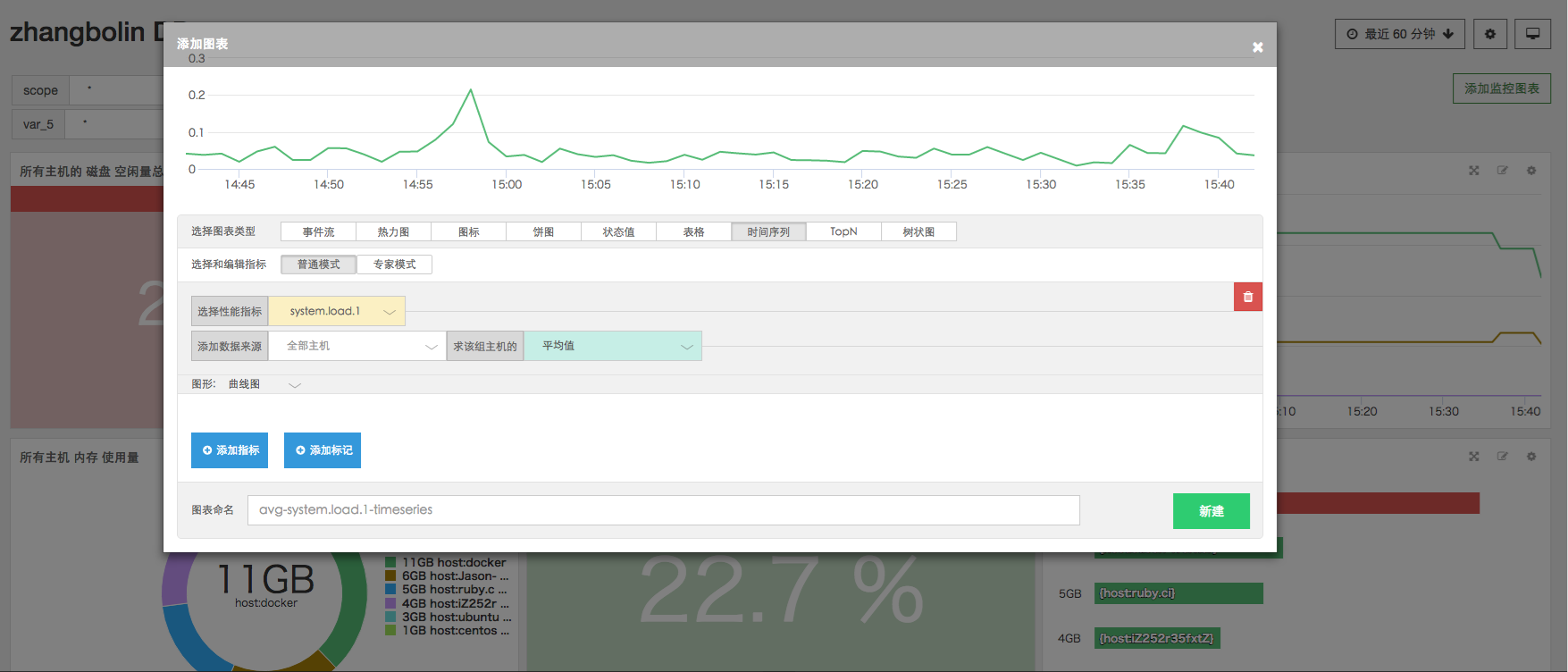
添加监控图表,会弹出以下对话框。使用 Cloud Insight 的 Metric 查询,就可以得到您所需要的图表。
目前 Cloud Insight 支持两种模式的指标查询,分别为普通模式与专家模式。普通模式的功能较为简单,并且可以在选择指标时即时查看指标含义。专家模式功能更为强大,操作更为简练,适用于专业运维工程师或对 OpentsDB 有一定了解的人士。
普通模式:
专家模式:
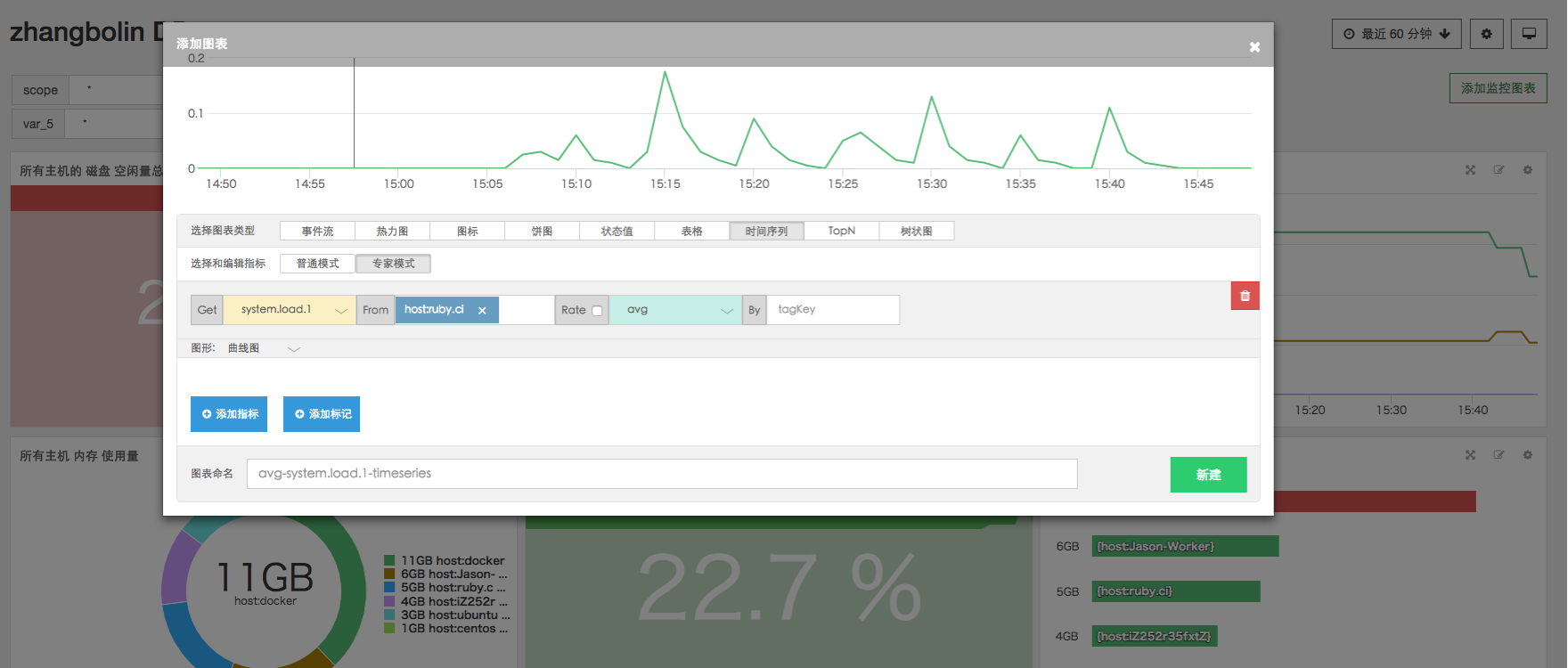
Cloud Insight 两种指标查询模式的界面与功能不完全相同,但基本逻辑是一致的,其可以提供一种类 SQL 的 Metric 查询方式。如果您了解过 OpentsDB,那就更容易上手了。在介绍具体的指标查询操作之前,首先介绍下 Metric 的查询逻辑与语法。
语法
Aggregation: MetricName {FromTag} by {TagKey}
在介绍语法前,我们先通过一组样本来解释 Metric 查询的语法。
| Series | MetricName | TagValue: Host | TagValue: Owner |
|---|---|---|---|
| A | system.cpu.idle | ChengMoMacAir | chengmo |
| B | system.cpu.idle | UbuntuChengMo | chengmo |
| C | system.cpu.idle | WZL-CentOS | wangzhili |
| Series | 00:00 | 01:00 | 02:00 | 03:00 | 04:00 | 05:00 |
|---|---|---|---|---|---|---|
| A | 0.3 | 0.5 | 0.1 | 0.2 | 0.8 | 0.1 |
| B | 0.8 | 0.3 | 0.7 | 0.8 | 0.9 | 0.3 |
| C | 0.6 | 0.2 | 0.4 | 0.6 | 0.1 | 0.1 |
Aggregation 和 FromTag
- Aggregation:聚合算子。指 Metric 查询范围 FromTag 所查询到的多条 series 通过 avg、max、min、sum 哪种方式聚合。
- FromTag:查询范围。指 Metric 所需聚合的 series 的查询条件。
如:
max: system.cpu.idle {host:ChengMoMacAir, host:UbuntuChengMO}
所得的结果是:
| Series | 00:00 | 01:00 | 02:00 | 03:00 | 04:00 | 05:00 |
|---|---|---|---|---|---|---|
| A | 0.3 | 0.5 | 0.1 | 0.2 | 0.8 | 0.1 |
| B | 0.8 | 0.3 | 0.7 | 0.8 | 0.9 | 0.3 |
| Output | 0.8 | 0.5 | 0.7 | 0.8 | 0.9 | 0.3 |
同样,上述查询也可以简化成:
max: system.cpu.idle {owner:chengmo}
这就是标签管理在 Cloud Insight 的重要性啦。该部分留到标签的章节,做详细的介绍。
by 其实就是 group_by
Cloud Insight 还支持类似 SQL 的 group_by 查询语法。这个在查看:
- 多个磁盘分区的容量
- Docker 中不同 Container 的性能消耗
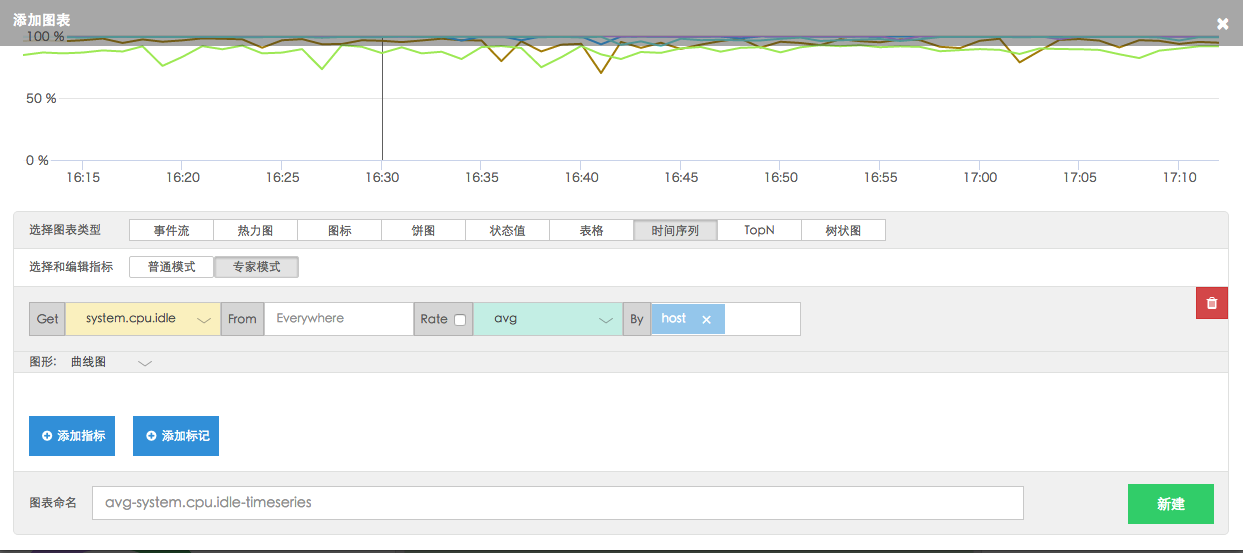
都是非常有用的。还是以上诉例子举例,如果我们想要看每个 host 的 CPU 空闲率:
avg: system.cpu.idle {} by {host}
此时,第一个 {FromTag} 缺省代表从所有 Metrics 中查询数据。如图所示,得到以下图表:
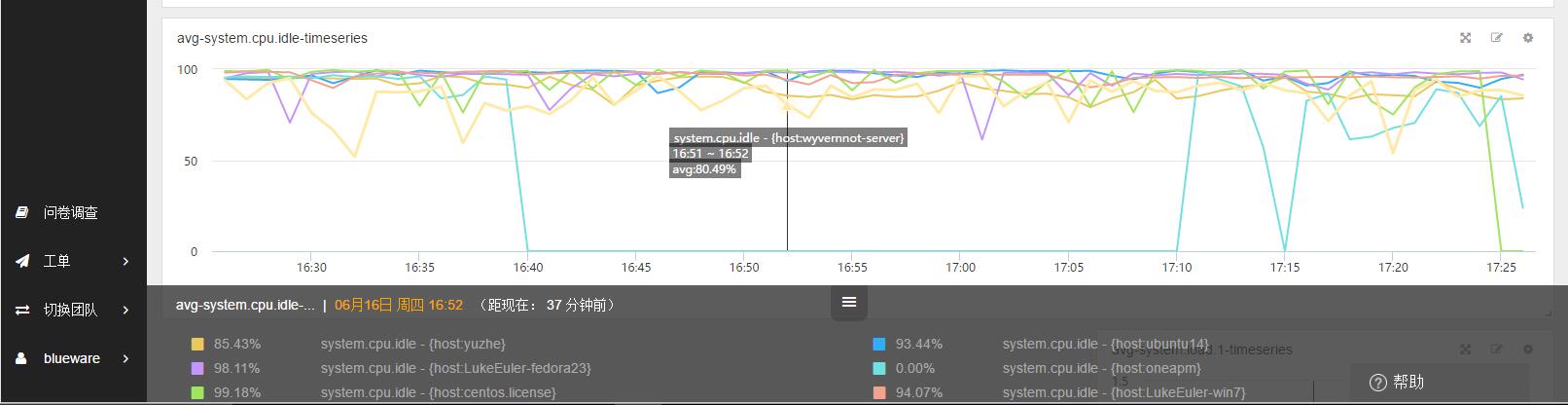
在实际的测试环境中,由于我们有 6 台测试主机,所以会得到如下的曲线。并且,当鼠标悬停至曲线时,下方的悬停窗口会分别显示 6 台主机的 system.cpu.idle。
灵活查询
聚合和分组并存
除开单纯的聚合和分组,Cloud Insight 还支持聚合和分组的复合查询。如:
avg: system.cpu.idle {} by {owner}
| Series | MetricName | TagValue: Host | TagValue: Owner |
|---|---|---|---|
| A | system.cpu.idle | ChengMoMacAir | chengmo |
| B | system.cpu.idle | UbuntuChengMo | chengmo |
| C | system.cpu.idle | WZL-CentOS | wangzhili |
此时,虽然有 3 个 host,但是分组是以 owner 来进行分组。所以,A 与 B 会聚合为一条曲线,而 C 和 A&B 的关系是分组的关系。
| Series | 00:00 | 01:00 | 02:00 | 03:00 | 04:00 | 05:00 |
|---|---|---|---|---|---|---|
| A | 0.3 | 0.5 | 0.1 | 0.2 | 0.8 | 0.1 |
| B | 0.8 | 0.3 | 0.7 | 0.8 | 0.9 | 0.3 |
| C | 0.6 | 0.2 | 0.4 | 0.6 | 0.1 | 0.1 |
| Output A&B | 0.55 | 0.4 | 0.4 | 0.5 | 0.85 | 0.2 |
| Output C | 0.6 | 0.2 | 0.4 | 0.6 | 0.1 | 0.1 |
多条件查询
FromTag 可以承接多个条件,如上文提到的:
max: system.cpu.idle {host:ChengMoMacAir, host:UbuntuChengMO}
查询到是两个 Host 的聚合结果。那么,如果是以下查询呢:
max: system.cpu.idle {host:ChengMoMacAir, owner:wangzhili}
此时,查询到结果为 NULL。因为,Metric 查询遵循以下原则:
- 同一 Tag Key,Metric 查询求并集;
- 不同 Tag Key,Metric 查询求交集。
也就是说,上述查询分别代表:
- 我想查询
host为ChengMoMacAir和host:UbuntuChengMO的聚合结果 - 我想查询
host为ChengMoMacAir且owner为wangzhili的聚合结果
自然,根据表格,我们发现这样的 Host 是不存在的,故而结果为 NULL。
我们之所以这么设计,是因为此类思考更符合人的思维习惯:
- 当人们选择多个 host 时,自然而然想到的是这些 host 的求和结果,即:同一 Tag Key 求并集;
- 当人们选择某个 host,又再次选择另一个 Tag 时,想到的是在这个 host 下满足这些 tag 的结果,即:不同 Tag Key 求交集。
注意:自定义的标签等价于 host 标签,在进行聚合运算时,host 和不同自定义标签之间均取并集。
普通模式
根据图表种类的不同,Metric 查询的普通模式可分为两种,主要区别在于是否支持 grop by,下面对这两种普通模式的操作进行简单的介绍。
如上图,在时间序列、状态值、热力图类型图表的指标选择普通模式中,主要包括三种功能:
- 选择性能指标,即在图表中显示哪种性能指标对应的数据
- 添加数据来源,即选择要查看该种数据的主机或标签,且仅可选择一个标签
- 选择聚合计算方式,即在所选数据包含多个主机的情况中,选择多个主机间的数据聚合方式
其中,在选择性能指标时会打开一个三级选择菜单,如下图
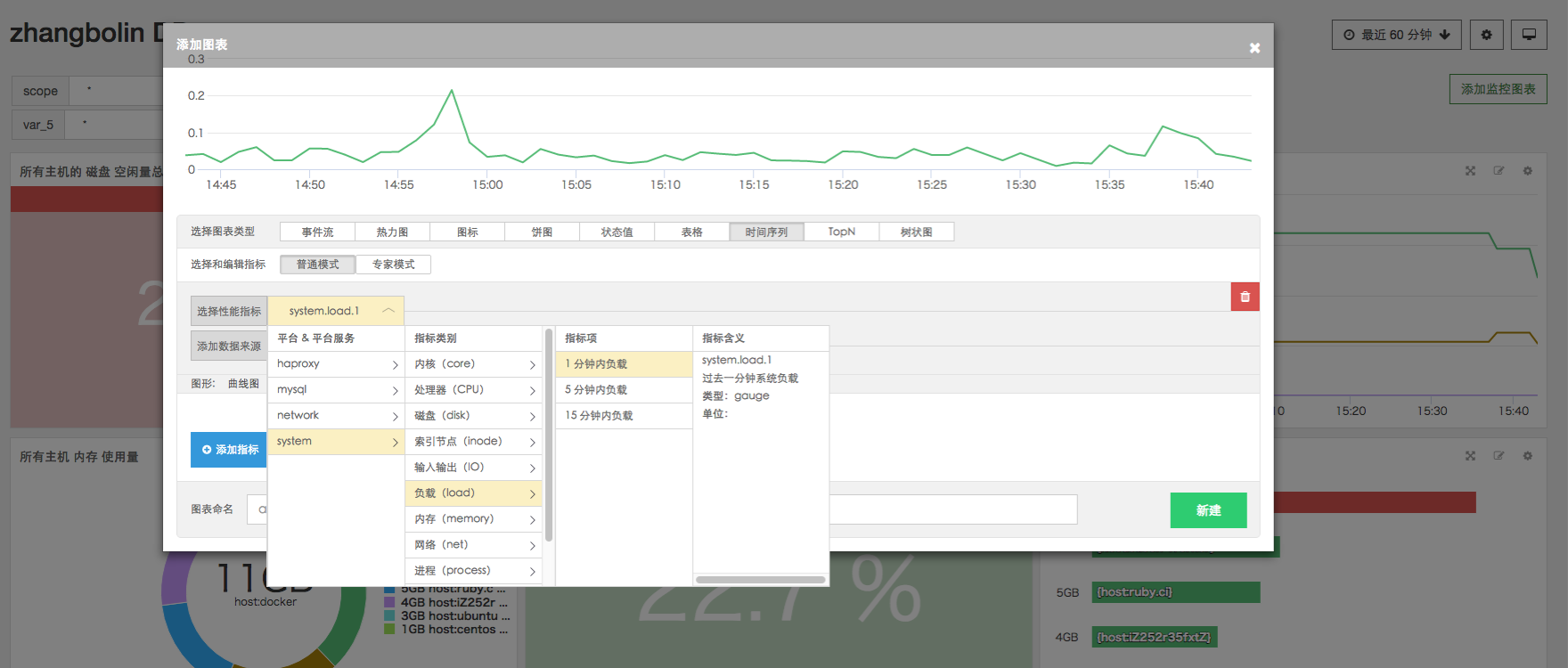
三级菜单分别对应选择 “平台&平台服务”、“指标类别”、“指标项”,而在菜单右侧可以直接查看选中的指标所对应的具体含义及类型、单位。
通过该菜单,您可以快速地选择自己想要查看的指标。同时如果您对指标的含义不甚了解,也可以在查看指标解释后再选择需要的指标。
并且,该指标选择菜单在所有图表的普通模式中保持一致。
而在饼图、排行榜、树状图、表格类型的图表中,普通模式的指标选择稍有不同
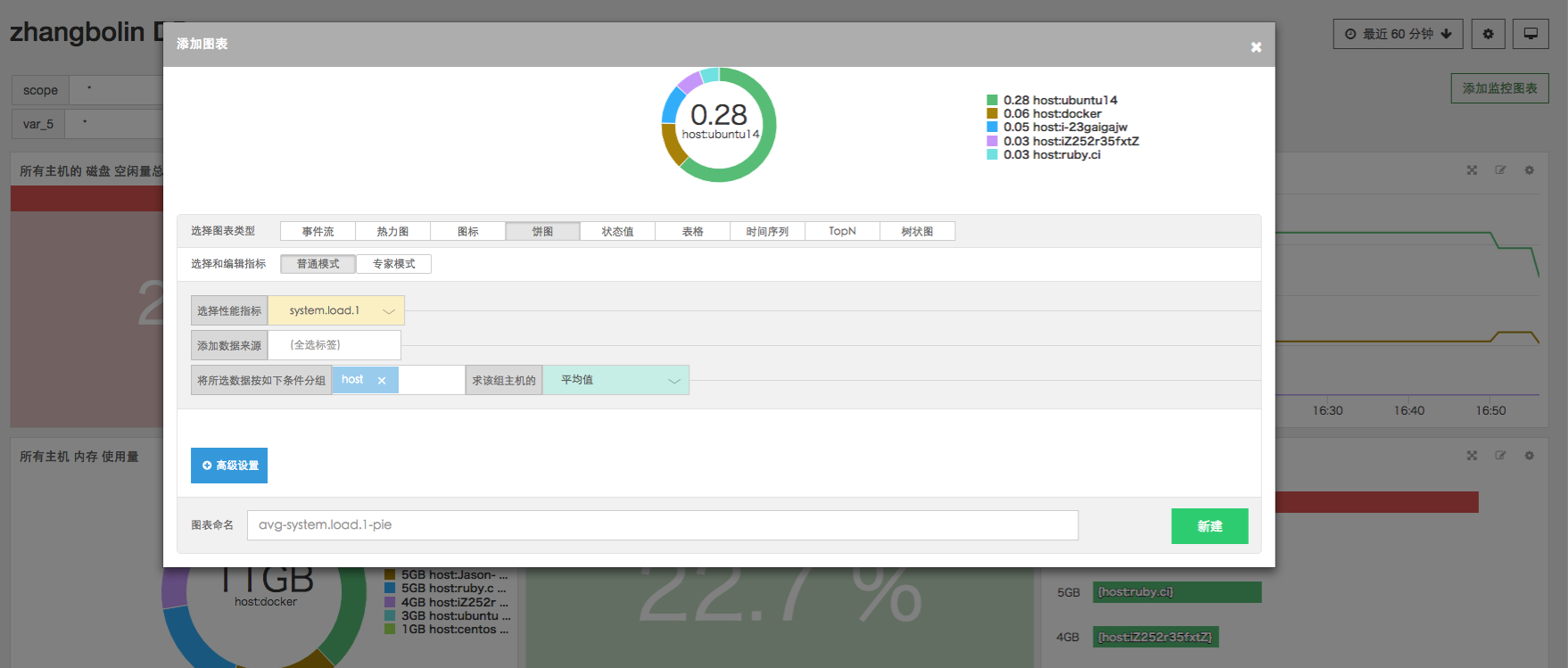
如上图,该普通模式增加了按标签分组的功能,即 grop by 的功能。并且,在创建图表时,默认将所选数据按照主机类型进行分组。
专家模式
如上图,指标选择的专家模式功能更加强大,除了普通模式支持的功能外,还增加了 rate 的功能,即查看所选指标的增长率。 并且,在 FromTag 功能中,可以选择多个不同类别的标签进行聚合筛选,选择更为精确的数据来源。
参数使用
Cloud Insight 还添加了参数来提取出 {FromTag},可以让用户不用每次都修改 {FromTag} 来查看 Metric;而只需在参数下拉框中选择 {FromTag} 来动态查询 Metric。
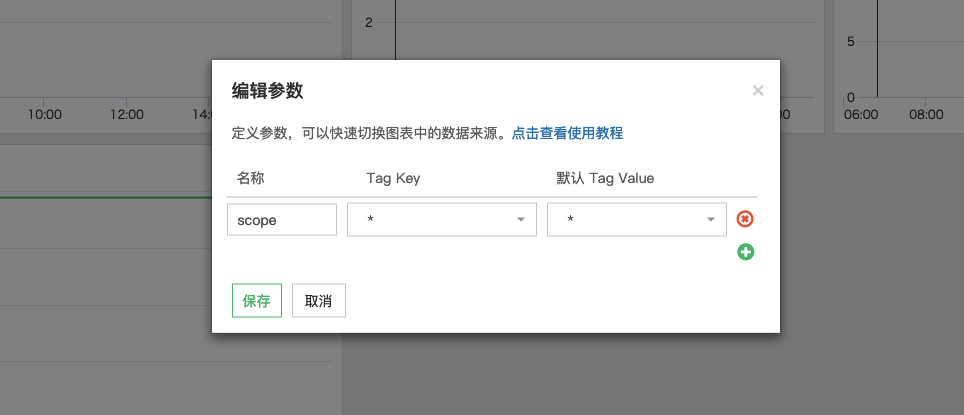
什么意思呢?我们先来温习下 Metric 查询的语法:
Aggregation: MetricName {FromTag} by {TagKey}
就是将 {FromTag} 设置为一个参数,可以让用户在界面做任意的更改。
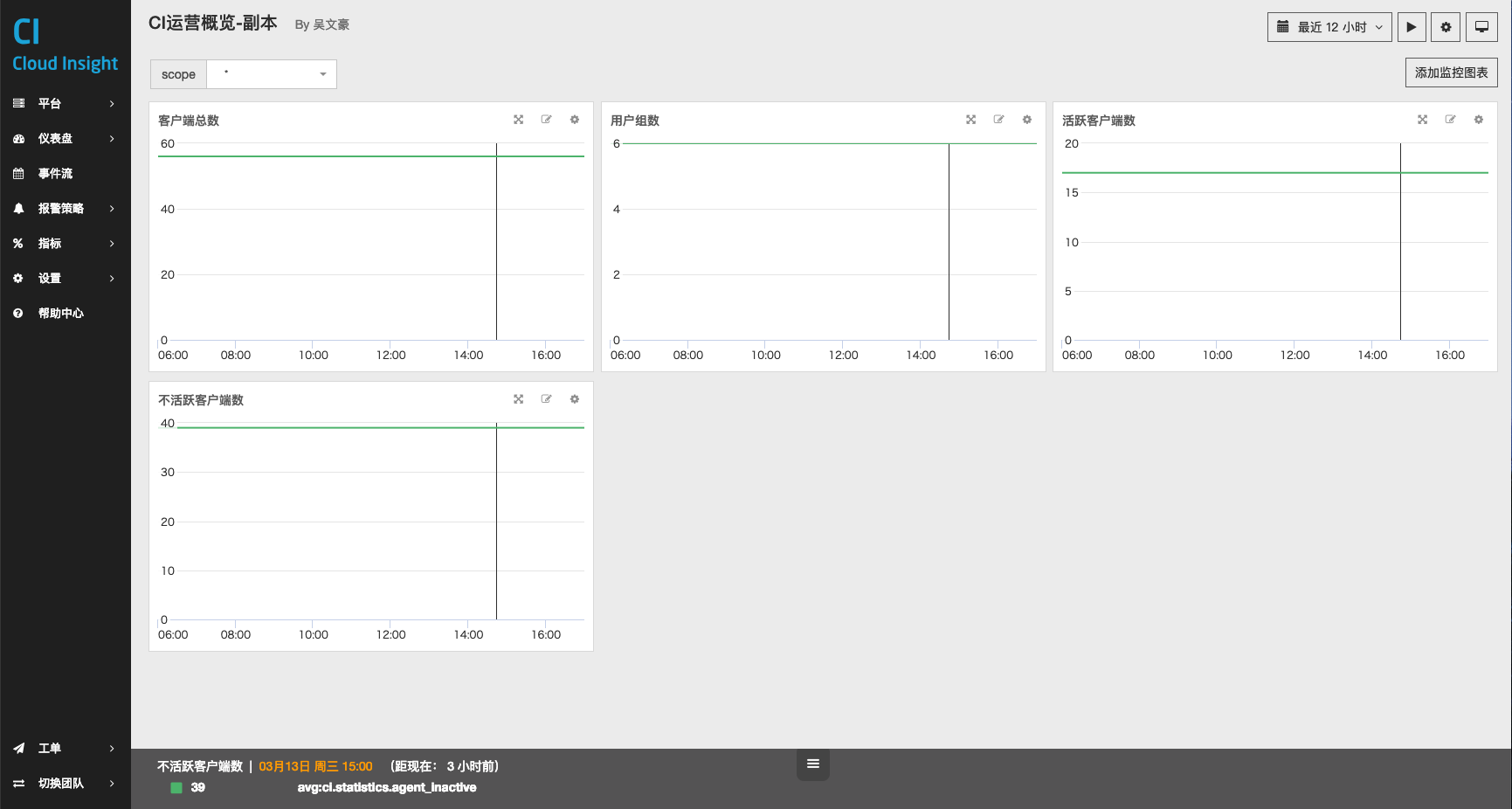
我们以 System 总览 • 仪表盘,举例来说:
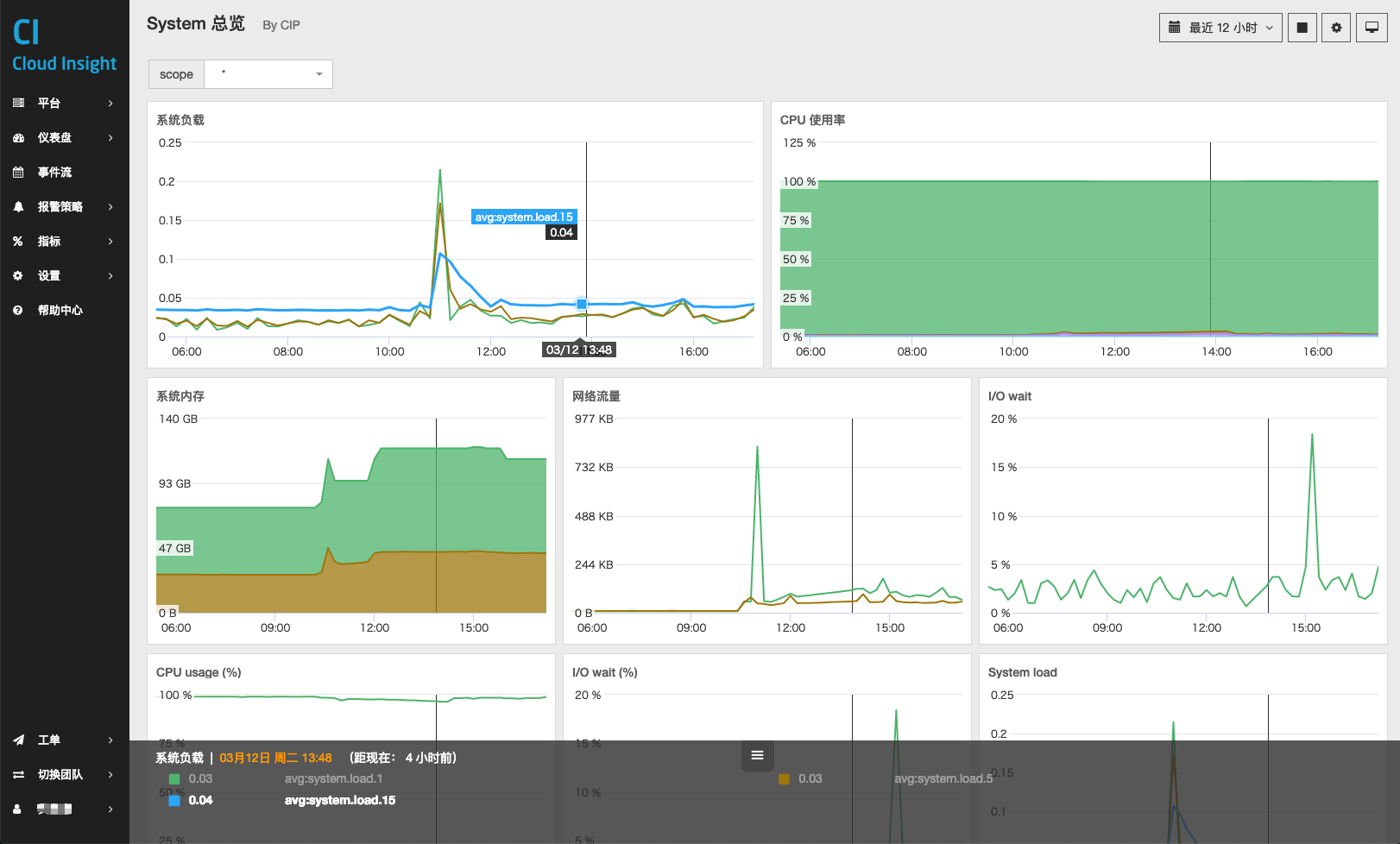
我们需要一张仪表盘,能够:
- 可以查看所有主机的总体性能;
- 又能够随时定位到单台主机的性能。
此时,就需要使用参数来达到要求。
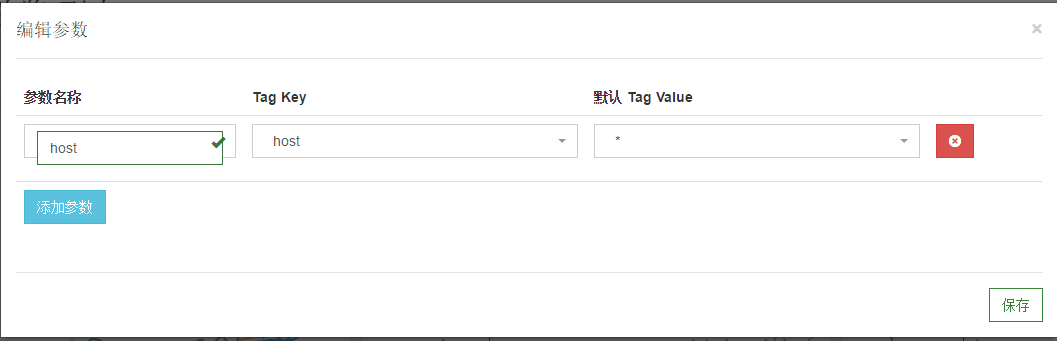
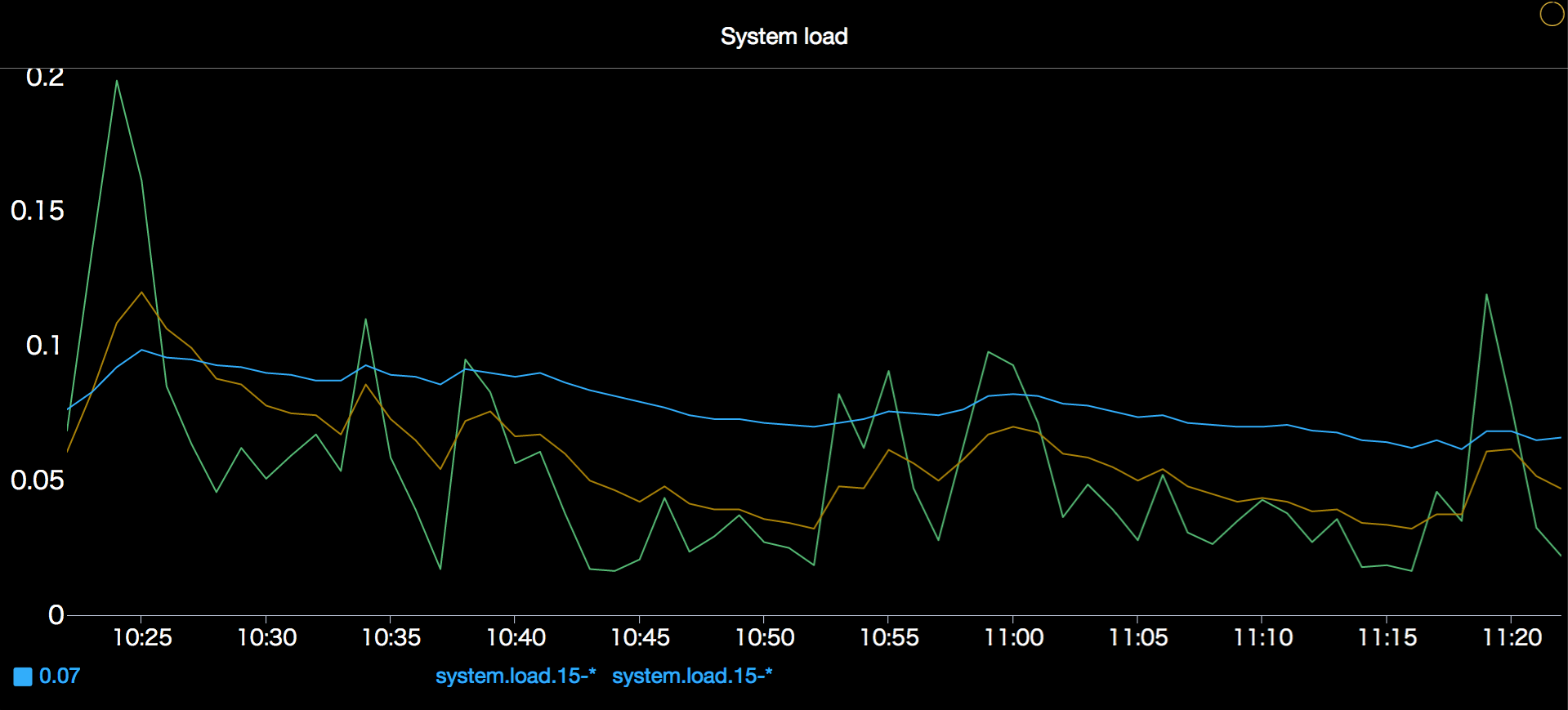
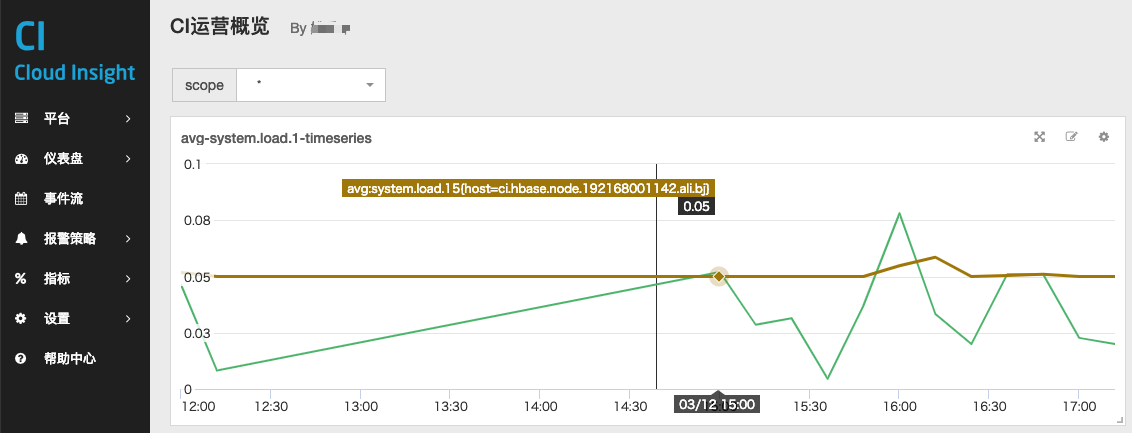
在上图中,我们可以看到 $scope 代表的是 host:* ,则此时 Metric 查询语句为:
avg:system.load.1 {host:*}
而之前监控图表设置的 Metric 查询为:
avg:system.load.1 {$scope}
是不是有点像 C 语言中宏的概念。也就是说,参数是一个可以根据下拉框随时被替换的字段,来满足动态查询。
若此时,我选择 $host 为 host:centos.license 则显示效果如图:
自定义仪表盘功能操作
随着版本不断更新迭代,仪表盘的功能也在不断丰富着,基本创建删除编辑功能参见仪表盘基本操作。
仪表盘图表类型
仪表盘图表类型现在有7种,热力图,饼图,状态值,表格,时间序列值,TopN,树状图下面一一介绍。
-
上图中
cpu use是默认的数据格式,数据是按照时间序列格式采集的,所以按照时间序列显示就是这样,其中这种是曲线图,此外还有面积图和柱状图。 -
上图中
cpu.user是热力图,数值大显示颜色深,可以查看最近一周服务器的 CPU 使用情况。 -
上图中
avg-system.load.1-top5是 TopN 数值。显示的是某个指标在一个维度的降/升序排列。 -
上图中
system load就是表格值,把当时的数据直接显示出来,很直观。 -
上图中
net_cvd就是状态值,其实是显示一个具体的指标数值,条件,阈值,背景颜色,字体颜色,字体位置等都可以设置,有具体的条件规则。 -
上图中
avg-system.disk.used-treemap是树状图,显示不同 device 所占磁盘大小。 -
上图中
mem也是时间序列格式的值,不过显示的是面积图。把一个服务器不同 device 的数据累积显示。 -
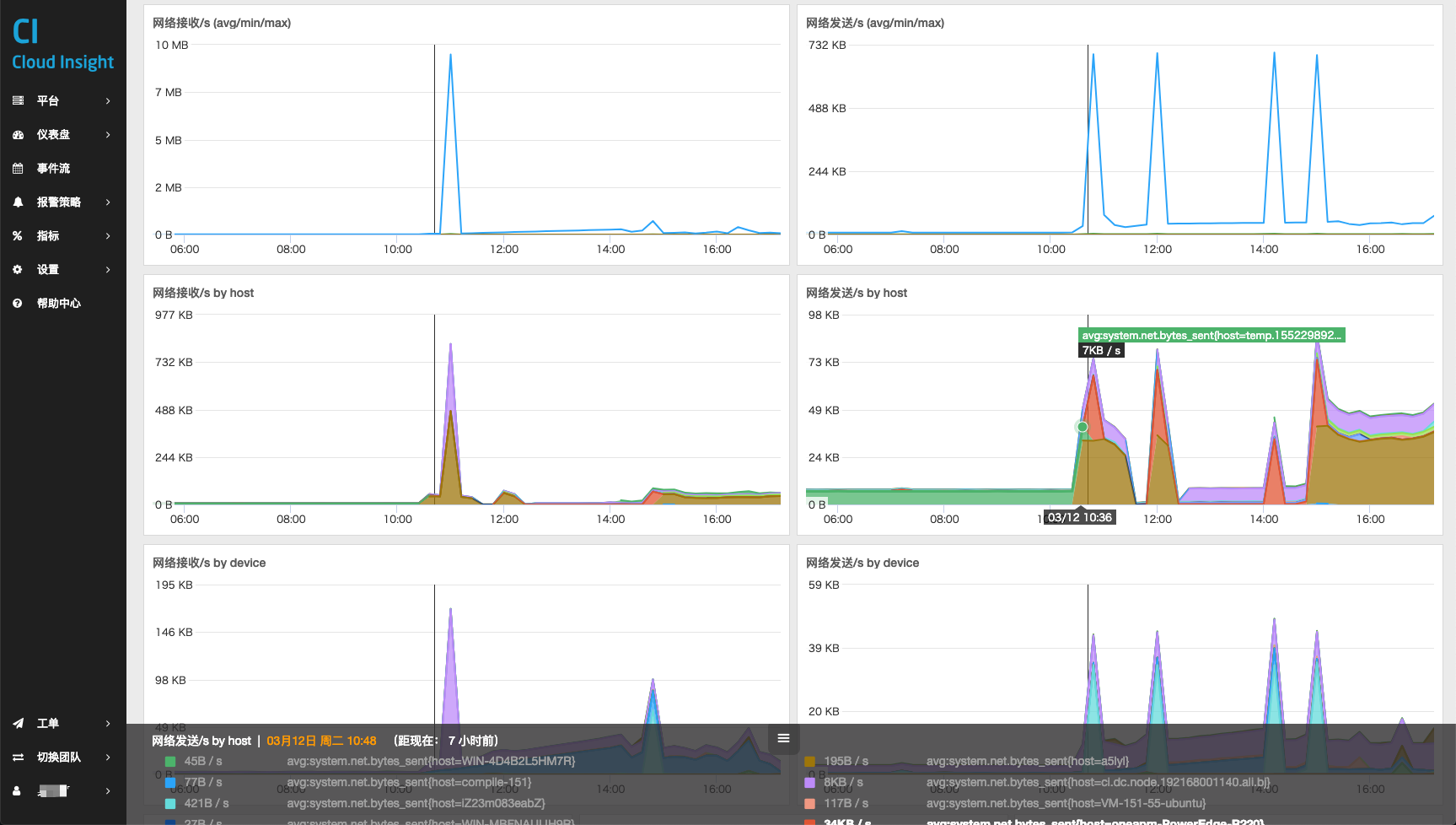
上图中
avg-system.net.bytes_sent-timesseries显示的是添加标记后的图表,对现有数据添加一个标记线/标记区域,可以警示数据到临界值的状况。 -
上图中
avg-system.load.1显示的是添加了叠加事件的状态,叠加事件和指标一同变化,从中看出发生某件事件时指标的变化情况。
此外,应该也看出来了图表大小可以调节,按照最舒适的角度随意调节。
显示 rate 增长率
仪表盘除了展示实时数据外,还可以展示 rate ,这点对于业务需求是很重要的,所有仪表盘类型都可以设置。设置方法很简单,点击勾选即可。
显示特定数据
默认的仪表盘会显示所有数据的总和,如果想显示特定数据就要用自定义仪表盘进行特别设置,基本操作原理参见 Metric 查询,本文以显示 Python 进程数为例。
想要监控 Python 进程,如果有进程挂了触发报警可以及时知道。具体配置见进程监控,配置好后,默认 process.threads 显示的是所有进程的数据。
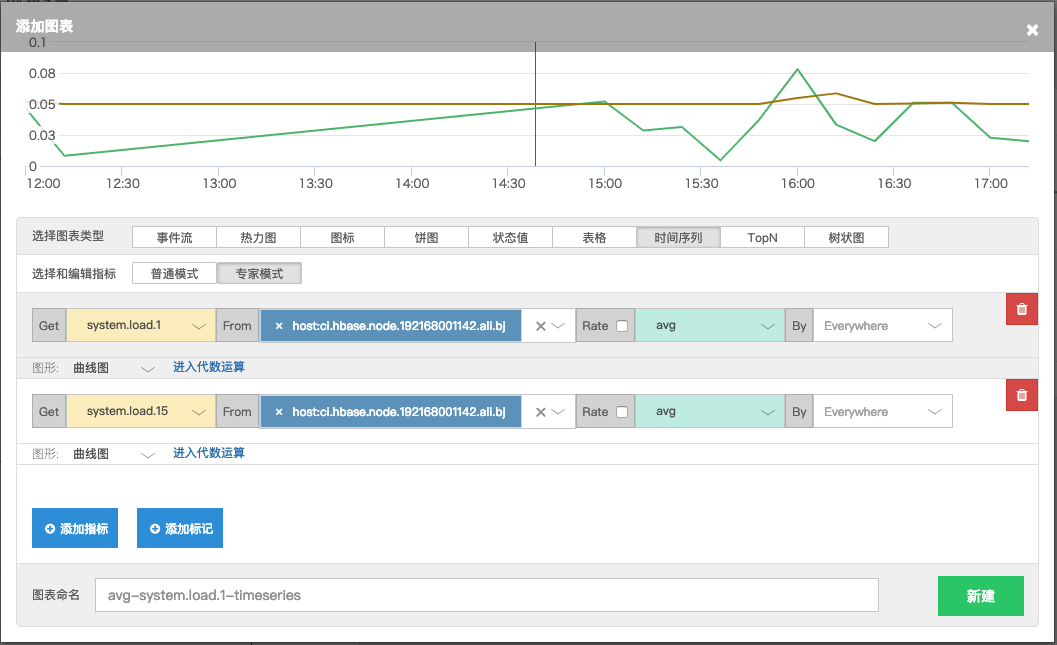
想要只显示 Python,先在指标处找到 process.threads 这个指标,看看其 Tags 是否有配置的如 process: python 这样的进程标签例,如果没有那就得看看有哪些配置错误,如果有的话就可以继续在仪表盘里面设置 Python 进程数仪表盘。
配置自定义仪表盘,先选定 process.threads 这个指标,再设置 From 指定查询范围,在选定前面的指标后,后面会列出只有此指标的 FromTag (即在指标中看到的那些 Tags),示例选了2个进程来监控,配置效果图如下:
同样的显示所有网卡流量情况也是这样配置。
叠加事件
仪表盘的叠加事件,是通过事件查询,符合名称的事件会在叠加到图表上显示。
关于什么是事件,参考事件流,为方便下面解释,现在举例:添加告警策略 avg(last_5m):avg:system.cpu.user {host:wzl-ubuntu} >= 9,策略名称设置为 wzl-ubuntu.cpu over 9(为了出数据,就这么设置了)这个会生成一个创建告警策略的事件,某一时刻到达报警条件,告警触发,几分钟后 CPU 又降了下来,告警策略关闭。这样一个过程会有3个事件,创建告警策略(info),告警触发(alert),告警恢复(info),后面是告警类别。
下面具体说一下叠加事件的查询条件,目前支持一下几种查询格式。
fieldname:value1,value2 和 value3 OR value4
其中:fieldname 为查询指定字段,value1,value2为可选值列表,value3和value4为不指定字段的全文检索
fieldname 可以使用以下:
event_title
event_type
alert_type
event_description
event_object
tags
host
source_type_name
可以输入 event_type:ALERT_TRIGGER ,这样就会把报警触发相关的信息都显示出来,还有一个就是中文的必须加双引号。
你可以搜索 event_title:wzl-ubuntu.cpu over 9,这样3种事件都会显示出来;也可以不加查询指定字段 fieldname,直接加 wzl-ubuntu.cpu over 9,同样会出现3种事件。
查询是累加的,如果想要删除某个查询条件只能先删除所有叠加事件,再重新添加。
全屏模式
点击仪表盘右上方的全屏按钮,可以进入全屏模式,来满足用户的投屏需求。
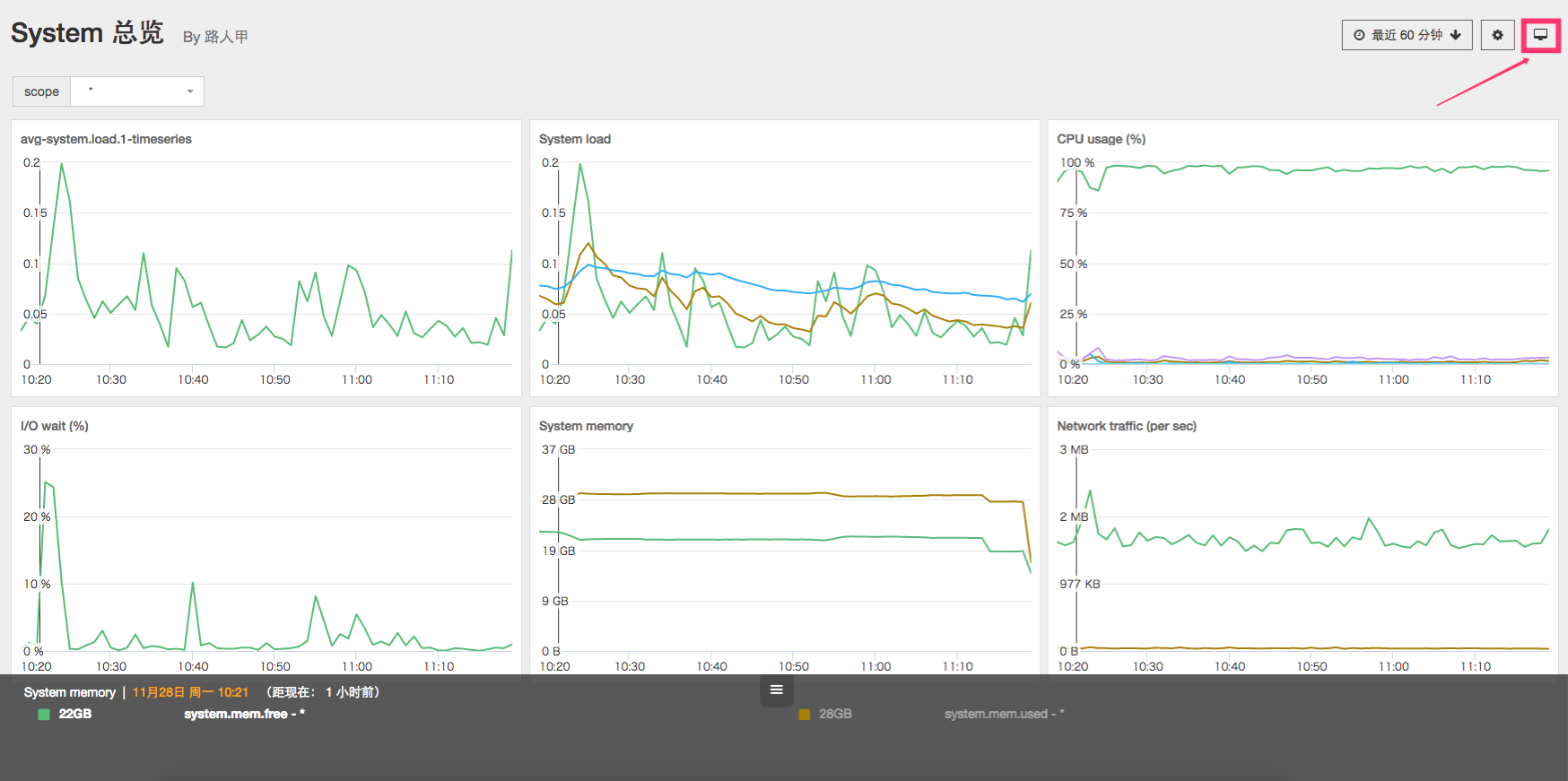
在全屏模式首页中,可选择具体要显示的图表、图表切换速度、是否锁定显示一张图表等。
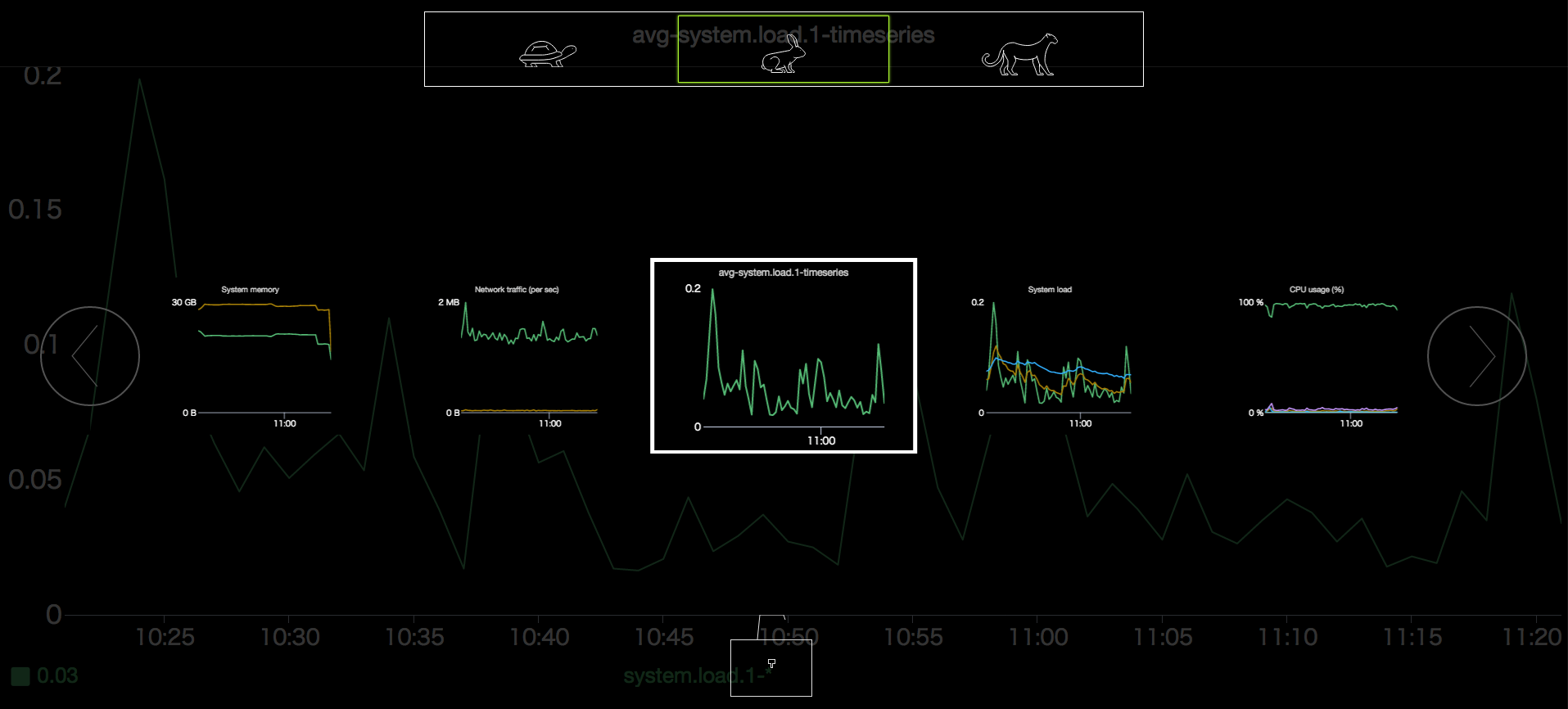
在全屏模式中,具体的操作方式如下:
- 点击仪表盘上方动物图标选择图表切换速度,其中由左至右按钮所对应的速度逐渐加快
- 直接点击图表缩略图或两侧左右箭头来选择图表
- 点击下方锁定按钮可锁定显示一幅图表,不进行自动切换,再次点击可解锁
- 在全屏首页保持无操作一定时间后可进入具体图表的全屏显示,并按所选速度切换显示不同图表
- 在显示具体图表时,进行任意操作可退出至全屏首页
- 使用 ESC 可退出全屏模式