
实时警报通知:微信告警通知的重要性解析
435
2023-07-12
AIOps 人工智能和IT运营支撑 Ops 之间的故事,愈演愈烈,已经成为当今运维圈的热门话题,我打算从2篇文档分享我们在 AIOps 上一些探索和实践。
现在的企业 IT 规模,软硬件都与以往有数十倍/上百倍递增,如何管理 IT 可用性和高效性,成为 IT 运营 DevOps 团队重要职责。规模化带来两个显著特点:1、更多的变更;2、更大的规模
企业的 IT 想跑的更快,就必须将工作给分解的更细,让团队能够以独立小分队作战。所以敏捷 Agile、DevOps、云和微服务大行其道。
为了保障高可用和高性能,现在企业基本上会用多个不同的工具,例如 Zabbix、Nagios、Open-Falcon、Solarwinds、Prometheus、ELK 等以及云平台自带的监控工具,实现网络和基础设施、应用和中间件等服务。这些系统每天会产生数以万计的事件/告警,这些时间都需要去分析、优先级甄别、并执行预案操作。随着时间的推移,可能是数十万、百万事件需要关注。
研究证明,人类大脑在短时间内(10-15秒),只能同时处理7-9件事情。这有点扯,习惯多线程工作的程序猿们,也就2-3个事情而已。所以工程师的生产效率其实是可期的。相信如果采用敏捷模式的工作模式,最后统计人均工作量(如 Jira)的时候,基本上一个团队/每个人的输出是一定量的。
这里就存在一个重要的矛盾:日益增长的 IT 运营需要,同落后的 IT 生产力之间的矛盾 :
以事件管理(告警管理)为例,我们看看人工智能结合后,有什么不同。事件管理是 IT 运营支撑过程中最为高频的事情,也是最费时费力的事情。
大多企业都有类似于 NOC,服务台或者是一线支持团队,及时分析、甄别重要事件,第一时间处理,如果处理不了,一般会协同他人,或者派发工单。这些有一个前提,一般都是有一个集中的事件中心(告警平台),例如 Cloud Alert。通过接口、邮箱等方式收集各类监控事件过来。
告警集中化便于集中处理事件的同时,也带来了一些问题:常见的是告警疲劳(太多事件无感)和噪音过多(不知道什么是重要的),重要事情淹没在汪洋大海里面。 一线团队识别重要问题的难度如大海捞针,所以大多人会做一个事情:禁用告警。只将需要处理的事件发送至告警平台,这样人为控制的方式,能够有效甄别;但也有问题,会有可能忽略大量的预警信息,不能及时在故障前发现问题;可能会造成对业务服务和终端用户的影响。
在进入AI模式前,有很多人包括 Cloud Alert 团队都在寻找合适的解决方案,常见的是事件的去重、关联、合并,尽可能识别根源,为此有些团队花巨大精力构建 CMDB、并强化拓扑关联等等,以及建立合并策略规则,目的只有一个,就是尽快甄别重要问题,以及识别根源,是否影响业务影响。然而事实证,大量的人为干预和规则设定,大量的前置规则,都需要投入,而实际产出可能各异,最终效果不见的理想。特别是在规模化(云化、分布式和动态微服务)以后,维持准确的 CMDB 和拓扑关联更加困难。
在谈 AIOps 前,我们先了解下什么是 AI。大数据发展、高性能硬件、更先进的算法三驾马车推进下,人工智能迎来第三轮发展浪潮。利用人工智能高效实现海量数据的分析和挖掘;处理数百万事件乃至千万,基本都是秒级甚至毫秒级。通过监督学习(人干预)和非监督学习(不干预),非常适合去处理大数据事情,这一点往往是人力达不到的。
Gartner 在2016年预测2019年,有25%的全球企业将会使用 AIOps 技术或平台去实现IT运营支撑,现在已经2018年,有理由相信下半年到明年 AIOps 的爆发。
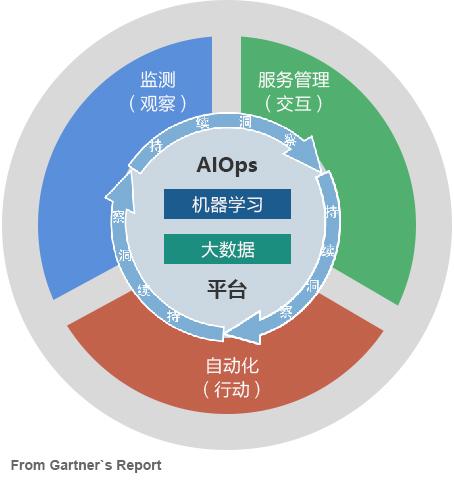
从 Gartner 定义范畴来说,AIOps 是包括监控 Monitor、服务管理 Service Desk、自动化操作Automation,基于大数据和机器学习技术的持续优化过程。核心思路是通过海量数据的异常检测和多维度关联飞、增强或取代 ITOM 领域的三个重要能力:监控、服务管理和自动化,进一步帮助IT运维人员准确甄别系统异常、快速定位故障根因、并对潜在系统运行风险进行预警、实现IT和业务的持续洞察和改进。
国内不少一线互联网企业已经在监控 Monitor 领域上做了不少尝试,而也有不少专业厂商在这领域发力。
今天讨论的其实重点是服务管理 ServiceDesk 的事件(告警)管理,实际上还有更多IT服务管理(ITSM)的人工智能化。我和团队的Cloud Alert事件处理平台,更多聚焦的是监控产生事件到人员处理响应这个过程,而且是一个高频场景,苦活累活较多。
我们对人工智能的期望是将数以万计的事件,经过漏斗式过滤,剩下的都是金子,缩减为数十个重要事情(不是单粒度事件),这样一线就可以保持更高的专注力和较高的工作效率。与传统人工模式相比,期望人工智能算法可以相对轻松的快速(秒级)处理事件,实现去重、关联和甄别重要事件,并创建工单/通知提醒,实现知识重用。
工程师通过人工智能技术辅助,可以更快更高效的处理重要事件,减少故障时间和业务中断时间,从而提升 IT 系统的可靠性和高性能。所以 AIOps 是一个新的途径,也是技术发展的必然选择。
我们期望事件(告警)处理可以实现:
(1)自动减少告警数量和噪音,去芜存菁。
(2)智能的关联/聚类能够快速的识别问题,分门别类。
(3)快速识别根源。
(4)协作自动化,实现团队沟通和协作。
(5)知识积累和自动复用,决策支持,越用越智能。
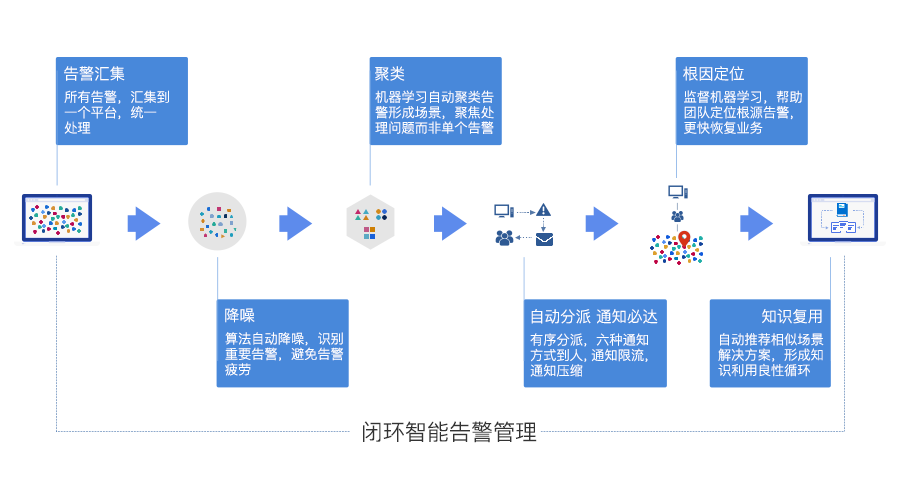
假设一个场景:
“某商城,网络交换机的端口故障,引发了一系列应用主机故障闪断(如 Zabbix Agent Ping),以及相关的商城和门户业务系统不稳定。”
Cloud Alert 的 AIOps 方案预期效果:
(1) 将短时间数百/数千事件,缩减至数类问题:网络交换机、主机闪断、应用商城不稳定和门户不稳定。
(2) 其中网络交换机端口故障和应用主机故障,需要重点关注,前者的根源概率为80%。
(3)上个月该交换机曾经出现过类似问题,解决方案是什么样的,如xx流量过大,需要限流干预。
(4) 自动通知相关基础设施团队、商城和门户支持团队。通知出问题,而不是某个业务系统100个进程闪断的逐条详细。
相比传统的人工方式,事无巨细的做法,人工智能的优势在于能够从大量的事件中提取关键重要信息,并甄别、识别优先级类型,并自动的实现人员协作通知,复用知识,实现决策支持,从而提升工作效率。


发表评论
暂时没有评论,来抢沙发吧~