
实时警报通知:微信告警通知的重要性解析
872
2023-07-05
IT运维领域要保障服务正常运行,通常第一步是将运维的对象监控起来,这其中主要就是对运维对象的指标进行实时监控:通过设定的(算法)规则对指标进行实时检测,当某个指标值不符合设定的规则时,则判定为异常,然后发送相应的告警到告警平台。
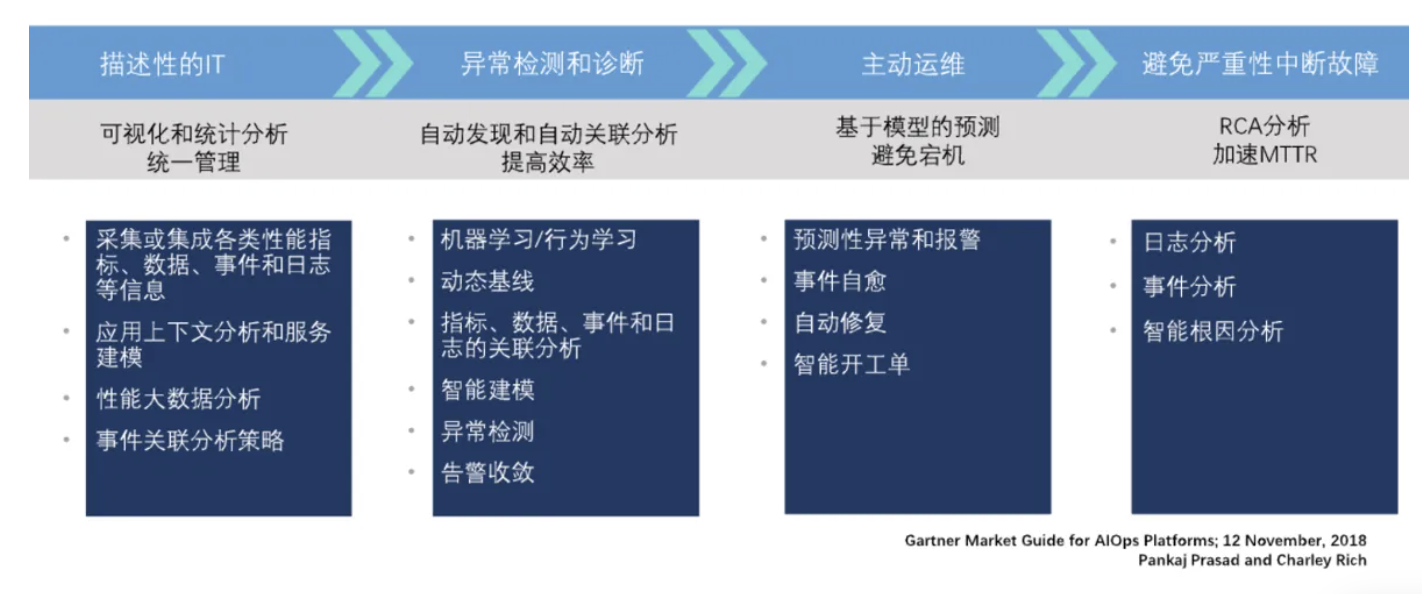
因为异常检测->告警策略->根因分析都是AIOps中非常关键的步骤,所以才拿出来单独讲;前面的笔记对异常检测做了总结,但检测算法给出的判断其实还需要经过综合判定、重要性排序、智能降噪收敛等手段,或者说告警策略才可以抵达用户面前,以降低异常检测算法误判、异常过多、不重要异常频报等现象给运维工作带来的负担。
通常告警策略模型是和业务类型、用户偏好以及应用场景等业务因素密切相关的,因为它是用来解决不同场景下的某一特定问题的。
通常来说告警策略模型的构建有以下几个思路:
专家根据经验或者算法根据历史数据设置阈值参数:由业务专家根据关键指标的特性和应用的关键需求指定一些简单的过滤器,从而筛选掉一部分疑似异常;或者通过算法自动化配置这个参数,但往往依赖以往的历史数据做模型训练,从而获得阈值(比如,频繁出现的异常往往可能是重要性比较弱的异常,不做告警大概率也不会对系统造成严重影响)
score机制:从异常的持续性出发考虑,如果连续发生几个异常,或者在某一段时间内累积发生多少个异常,则触发报警。
vote机制:多种算法组合进行异常判断,比如上游的异常检测模型使用了多个算法来进行异常判断,当多个算法都报异常的时候才进行告警;或者当多个算法的异常指数累积超过某值后才进行告警(这样会带来召回率低的问题,需结合业务场景考虑)
反馈机制:提供交互工具让运维人员/用户反馈异常告警是否准确or是否为重要异常,根据标注数据训练分类器,以此来判断某一个疑似异常是否该告警。
上述的几个思路更多还是侧重于单个指标异常告警的策略上,那如果是一个大的应用系统,包含了业务层/应用层/网络层/系统层/数据层等n个维度的监控指标,每天可能会产生万级的不同类型的异常告警,这时候就衍生出侧重系统工程方面的告警策略考量:
当发生大范围产生报警时,要具备有能力对报警进行聚类收敛或者基于关联规则的报警合并,比如按事件、按集群、按设备等维度进行聚类再报,避免报警洪潮;当运维人员接单处理时再支持细节展开与记录查看,有助于异常的解决和定位。
支持多种报警手段,如微信、邮件、短信等,发现问题第一时间通知系统管理员
告警平台收到告警后,会分配给对应的运维人员进行处理,运维人员根据告警信息来排查问题所在,最终定位故障的根本原因,并对故障进行修复。
从这个流程可以看出,整个过程是以告警为中心,所以告警的质量至关重要。那么,如何保证指标类告警的质量呢,这就需要使用准确有效的(算法)规则来对指标进行异常检测了。
1.规模庞大
随业务发展的大规模系统和设备导致需要监控的指标呈指数型增加。
2. 指标类型多样化
不同的系统和业务,其指标的形态千变万化,没有单一不变的方法可以覆盖所有的指标情况。
因此,要提高指标异常检测的效率和准确性,降低告警的误报率及漏报率,我们要从以上两个问题点出发去解决单指标异常检测的问题。
在探讨问题的解决方案之前,这里先给单指标异常检测的相关概念做一个陈述:
时间序列:是一组按照时间发生先后顺序进行排列的数据点序列。时间序列的时间间隔为此时序数据的频率。
异常:在时间序列中,异常是指在一个或多个信号的模式发生意料之外的变化。
所以,单指标异常检测即对单个变量的时间序列数据进行异常发现的过程。在运维领域内,cpu、mem、disk等资源的使用量、网络流量等指标的异常检测都属于单指标异常检测。

▲ 图片来源谷歌,如有侵权请联系删除
通过上面的内容,我们对单指标异常检测有了大致的了解,下面来讲述如何实现它。
指标分类
首先我们来解决上面提到的问题二——指标类型多样化的问题。时序数据的形态各异(如下图),如何通过一种有效的分类方式将时序数据分类呢?
 ▲ 图片来源谷歌,如有侵权请联系删除
▲ 图片来源谷歌,如有侵权请联系删除
假设一条时间序列是由多种成分相加得来,那么它可以写为如下形式:
y(t)=S(t)+T(t)+R(t)
其中S(t)、T(t)、R(t)分别是周期成分(seasonal component)、趋势成分(trend-cycle component)、残差成分(remainder component)。如下图,将原始时序数据data通过STL分解为三种分量(trend、seasonal、remainder)之和。
此外,时间序列也可以写成相乘的形式(对于乘性模型,可以取对数(当然是有意义的前提下,将其转化为加性模型):
y(t)=S(t)×T(t)×R(t)

▲ 图片来源谷歌,如有侵权请联系删除
至此,我们的问题转变为:用什么方法判断曲线的类别(趋势型、季节型、波动型)?下面介绍常用的两种方式:
① 皮尔逊相关系数(PCCs)判别法
通过时序数据的分解算法将原始数据分解为3个分量,而后分别计算三个分量与原始数据的皮尔逊相关系数,取系数最大的分量作为曲线的类别(如最大系数差别较小,可划分此曲线同属2个类别)。(分解法包括:经典分解法、X11分解法、SEATS分解法、STL分解法等)
② 依据人工设定阈值的判别法
是否是波动型:计算时序数据的标准差,并和设定好的阈值(人工经验)来进行比较得出。
是否是趋势型:EWMA平滑处理时序数据,而后通过一元线性回归拟合曲线,通过对y=kx+b的k值与设定好的阈值比较得出曲线是否是趋势型。
是否是季节性:对于非波动型数据不做季节性判断;对于波动型数据,获取当天、上一天、上周的同一天数据,归一化处理后分别计算当天与另外两天的MSE,取其中较小值与设定好的阈值进行比较得出曲线是否是季节型。
2. 对应检测模型构建
针对问题一——指标数据规模庞大的问题,这就使得无监督的算法相较于有监督算法、简单模型相较于复杂模型具有更大的优势:节省人力+普适性强+检测效率高。在实际用过程中,一般会对每种类型的指标进行2种及以上的算法模型检测,并对结果进行投票决策,提高检测准确率。(注:考虑到延迟,同比环比算法都是相较于过去的某个时间范围而不是对应的时间点)发现故障是告警质量的决定性环节,指标异常检测作为运维故障发现-分析-处理流程的开始阶段,它的一分准确可以避免后续的十分、一百分的劳动。
好的指标异常检测方法一方面能够使得告警质量大大提升,另一方面能够减少运维人员对阈值设定的繁琐工作量,对于整体的运维质量起着至关重要的作用。
首先,应该明确监控报警异常的原因。监控报警异常一般是由于硬件故障、软件故障或者人为因素造成的。硬件故障是指机器的硬件部分出现故障,导致监控报警异常。软件故障是指软件运行出现错误,导致监控报警异常。人为因素造成的监控报警异常主要是指人为操作不当,导致监控报警异常。
其次,根据监控报警异常的原因制定解决方案。硬件故障造成的监控报警异常,应该尽快安排维修人员进行维修。软件故障造成的监控报警异常,应该尽快调整软件的设置,使其能够正常运行。人为因素造成的监控报警异常,应该加强人员的培训,使其能够正确操作监控设备。
综上所述,要想解决监控报警异常的问题,首先应该弄清楚监控报警异常的原因,其次根据监控报警异常的原因制定解决方案。


发表评论
暂时没有评论,来抢沙发吧~