监控数据的可视化分析神器 Grafana 的告警实践
1801
2022-10-20
本文目录一览:
统一监控平台,说到底本质上也是一个监控系统,监控的基本能力是必不可少的,回归到监控的本质,先梳理下整个监控体系:
① 监控系统的本质是通过发现故障、解决故障、预防故障来为了保障业务的稳定。
② 监控体系一般来说包括数据采集、数据检测、告警管理、故障管理、视图管理和监控管理6大模块。而数据采集、数据检测和告警处理是监控的最小闭环,但如果想要真正把监控系统做好,那故障管理闭环、视图管理、监控管理的模块也缺一不可。
一、数据采集
1、采集方式
数据采集方式一般分为Agent模式和非Agent模式;
Agent模式包括插件采集、脚本采集、日志采集、进程采集、APM探针等
非Agent模式包括通用协议采集、Web拨测、API接口等
2、数据类型
监控的数据类型有指标、日志、跟踪数据三种类型。
指标数据是数值型的监控项,主要是通过维度来做标识。
日志数据是字符型的数据,主要是从中找一些关键字信息来做监控。
跟踪型数据反馈的是跟踪链路一个数据流转的过程,观察过程中的耗时性能是否正常。
3、采集频率
采集频率分秒级、分钟级、随机三种类型。常用的采集频率为分钟级。
4、采集传输
采集传输可按传输发起分类,也可按传输链路分类。
按传输发起分类有主动采集Pull(拉)、被动接收Push(推)
按传输链路分类有直连模式、Proxy传输。
其中Proxy传输不仅能解决监控数据跨网传输的问题,还可以缓解监控节点数量过多导致出现的数据传输的瓶颈,用Proxy实现数据分流。
5、数据存储
对于监控系统来说,主要有以下三种存储供选择
① 关系型数据库
例如MySQL、MSSQL、DB2;典型监控系统代表:Zabbix、SCOM、Tivoli;
由于数据库本身的限制,很难搞定海量监控的场景,有性能瓶颈,只在传统监控系统常用
② 时序数据库
为监控这种场景设计的数据库,擅长于指标数据存储和计算;例如InfluxDB、OpenTSDB(基于Hbase)、Prometheus等;典型监控系统代表:TICK监控框架、 Open-falcon、Prometheus
③ 全文检索数据库
这类型数据库主要用于日志型存储,对数据检索非常友好,例如Elasticsearch。
二、数据检测
1. 数据加工
① 数据清洗
数据清洗比如日志数据的清洗,因为日志数据是非结构化的数据,信息密度较低,因此需要从中提取有用的数据。
② 数据计算
很多原始性能数据不能直接用来判断数据是否产生异常。比如采集的数据是磁盘总量和磁盘使用量,如果要检测磁盘使用率,就需要对现有指标进行一个简单的四则运算,才能得到磁盘使用率。
③ 数据丰富
数据丰富就是给数据打上一些tags标签,比如打上主机、机房的标签,方便进行聚合计算。
④ 指标派生
指标派生指的是通过已有的指标,通过计算得出新的指标。
2. 检测算法
有固定规则和机器学习算法。固定算法是较为常见的算法,静态阈值、同比环比、自定义规则,而机器学习主要有动态基线、毛刺检测、指标预测、多指标关联检测等算法。
无论是固定规则还是机器学习,都会有相应的判断规则,即常见的 =和and/or的组合判断等。
三、告警管理
1. 告警丰富
告警丰富是为了后续告警事件分析做准备,需要辅助信息去判断该怎么处理、分析和通知。
告警丰富一般是通过规则,联动CMDB、知识库、作业历史记录等数据源,实现告警字段、关联信息的丰富;通过人工打Tags也是一种丰富方式,不过实际场景下由于人工成本高导致难以落地。
2. 告警收敛
告警收敛有三种思路:抑制、屏蔽和聚合
① 抑制
即抑制同样的问题,避免重复告警。常见的抑制方案有防抖抑制、依赖抑制、时间抑制、组合条件抑制、高可用抑制等。
② 屏蔽
屏蔽可预知的情况,比如变更维护期、固定的周期任务这些已经知道会发生的事件,心里已经有预期。
③ 聚合
聚合是把类似或相同的告警进行合并,因为可能反馈的是同一个现象。比如业务访问量升高,那承载业务的主机的CPU、内存、磁盘IO、网络IO等各项性能都会飙升,这样把这些性能指标都聚合到一块,更加便于告警的分析处理。
3. 告警通知
① 通知到人
通过一些常规的通知渠道,能够触达到人。
这样在没有人盯屏的时候,可以通过微信、短信、邮件触发到工作人员。
② 通知到系统
一般通过API推送给第三方系统,便于进行后续的事件处理
另外还需要支持自定义渠道扩展(比如企业里有自己的IM系统,可以自行接入)
四、故障管理
告警事件必须要处理有闭环,否则监控是没有意义的。
最常见还是人工处理:值班、工单、故障升级等。
经验积累可以把人工处理的故障积累到知识库里面,用于后续故障处理的参考。
自动处理,通过提取一些特定告警的固化的处理流程,实现特定场景的故障自愈;比如磁盘空间告警时把一些无用日志清掉。
智能分析主要是通过故障的关联分析、定位、预测等AI算法,进一步提升故障定位和处理的效率;
1. 视图管理
视图管理也属于增值性功能,主要是满足人的心理述求,做到心中有底,面向的角色很多(领导、管理员、值班员等)。
大屏:面向领导,提供全局概览
拓扑:面向运维人员,提供告警关联关系和影响面视图
仪表盘:面向运维人员,提供自定义的关注指标的视图
报表:面向运维人员、领导,提供一些统计汇总报表信息,例如周报、日报等
检索:面向运维人员,用于故障分析场景下的各类数据检索
2. 监控管理
监控管理是企业监控落地过程中的最大挑战。前5个模块都是监控系统对外提供的服务功能,而监控管理才是面向监控系统自身的管理和控制,关注真正落地的过程的功能呈现。主要有以下几个方面:
配置:简单、批量、自动
覆盖率:监控水平的衡量指标
指标库:监控指标的规范
移动端:随时随地处理问题
权限:使用控制
审计:管理合规
API:运维数据最大的来源,用于数据消费
自监控:自身稳定的保障
为了实现上述监控六大基础能力模块,我们可以按如下架构设计我们的统一监控平台。
主要分三层,接入层,能力层,功能层。
接入层主要考虑各种数据的接入,除了本身Agent和插件的采集接入,还需要支持第三方监控源的数据接入,才能算一个完整的统一监控平台。
能力层主要考虑监控的基础通用能力,包含数据采集模块、数据存储模块、数据加工模块、数据检测模块、AI分析模块。
功能层需要贴近用户使用场景,主要有管理、展示两类功能,在建设的过程中可以不断丰富功能场景。
另外,考虑到数据的关联关系,为未来的数据分析打下基础,监控和CMDB也需要紧密联动,所有的监控对象都应该用CMDB进行管理,另外,还可以配置驱动监控为指导理念,实现监控的自动上下线,告警通知自动识别负责人等场景,简化监控的维护管理。
为了统一监控平台能够在企业更好的落地,我们需要配备对应的管理体系,其中最重要的是指标管理体系。
指标管理体系的核心理念:
监控的指标体系是以CMDB为骨架,以监控指标为经脉,将整个统一监控平台的数据有机整合起来。
贯穿指标的生命周期管理,辅以指标的管理规范,保障监控平台长久有序的运行。
从企业业务应用的视角出发,一般将企业监控的对象分为6层,也可以根据企业自己的情况进行调整:
基础设施层
硬件设备层
操作系统层
组件服务层
应用性能层
业务运营层
视频监控终端实时告警
1.电脑监控软件能进行屏幕录像功能,可以多画面截图记录QQ、微信、聊天、邮件、搜索、微博、论坛、游戏、求职、网盘、赌博、色情、视频、购物,还能自定义。
2.还能同时监控多个画面,能同时展示一个或者多个电脑实时屏幕,多同时显示16个电脑画面,点击可以放大单独查看,并可以进行远程桌面控制。
3.对网址、搜索引擎、文件操作记录、程序运行记录、邮件记录、报警记录,清晰记录访问网站开始和结束时间。
4.还能根据使用者的需求,操作软件运行,可以结束电脑进程。
5.同时提供文件管理功能,文件管理支持下载。
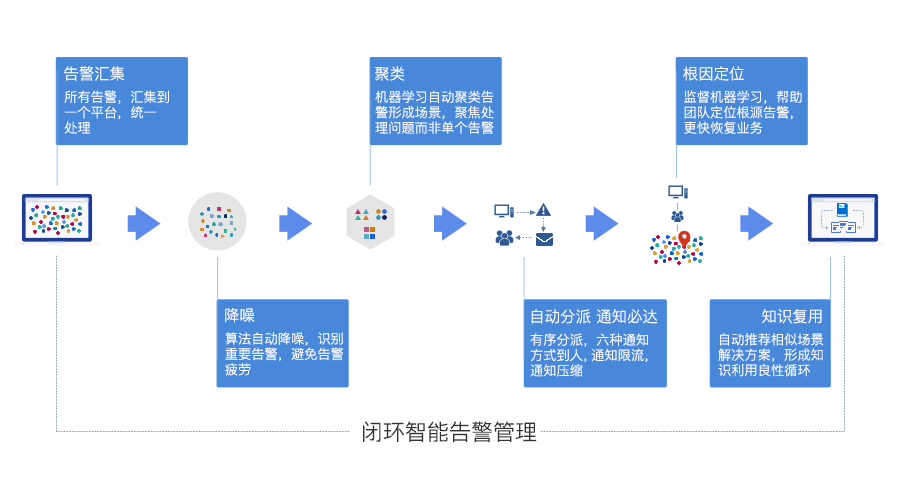
由于监控项较多,当一起产生告警时,运维人员会应接不暇。云帮手通过告警信息分类展示,让用户可自行选择查看某一项告警信息,能够减少遗漏,快速找到问题根源并处理;同样,有效的日志分类能够帮助用户及时查看到自己某一项的操作记录,快速追溯到问题根源,提高运维效率。
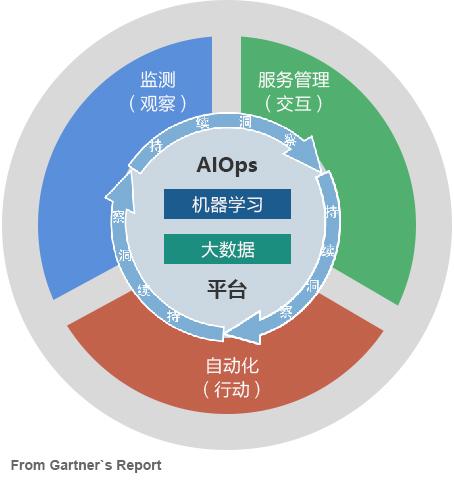
通常智能运维中的告警收敛场景,以机器学习算法为驱动,对海量的告警事件进行降噪和关联分析,辅助根因定位并可沉淀故障处理的知识,从而提升企业的运维效率,降低运维成本。 告警产生后,AIOps系统通过算法甄别 内容相关性(重复性、相似性)、时序相关性和拓扑相关
性 事件来进行告警事件的自动化抑制。这类收敛抑制,往往能得到99%的告警压缩率,极大地提高了告警有效性。
在一个完整的智能运维告警产品里,除了告警收敛,还可以基于故障传播链及拓扑信息 ( 可选 ), 智能发现突发故障场景;基于告警“熵值”算法,实现告警的动态优先级推荐;通过时序以及拓扑关系定位故障场景根因,并进行根因标记。当这些都可以完成时,由告警事件一步步引导的根因定位和排障,才是真正智能运维发挥了作用。
发表评论
暂时没有评论,来抢沙发吧~