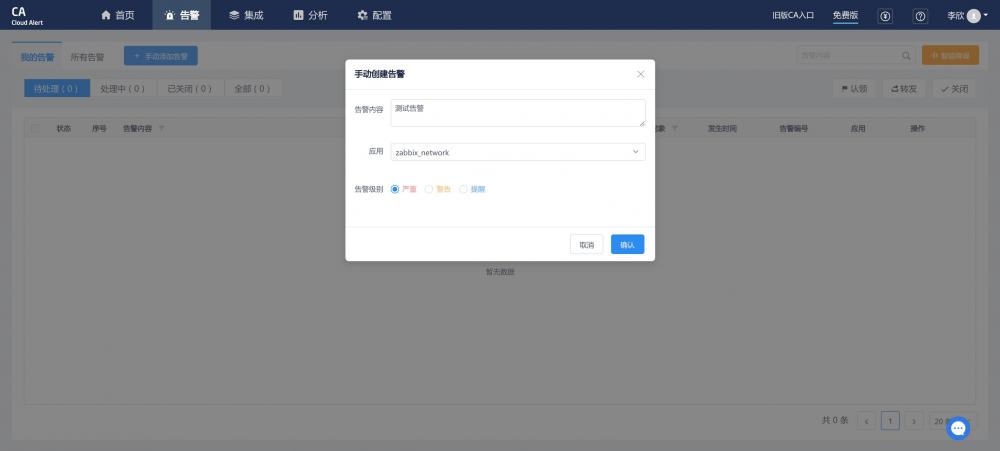
如何在智能告警平台CA触发测试告警
1604
2022-10-13
TiDB在北京顺丰同城科技的实践与应用(一)
一、应用场景介绍
目前TiDB在北京顺丰同城科技(以下简称北科)主要应用于智域系统(SDS),该系统将依赖从集团速运Kafka实时同步的海量数据。大容量存储能力、灵活扩展性、高效存取、高稳定性、高可用等特性,是我们对TiDB的基本要求。
伴随业务系统快速增长,如今TiDB集群以12节点的数量,支撑了每日约增量2.43亿的海量数据存储,本文也将重点从运维的角度,分享TiDB在北科的一系列应用实践和遭遇的挑战。
二、为什么选择TiDB
2.1 TiDB特点
TiDB 结合了传统的 RDBMS 和 NoSQL 的最佳特性,兼容 MySQL 协议,支持无限的水平扩展,具备强一致性和高可用性。
具有如下的特性:
高度兼容 MySQL,大多数情况下无需修改代码即可从 MySQL 轻松迁移至 TiDB,即使已经分库分表的 MySQL 集群亦可通过 TiDB 提供的迁移工具进行实时迁移。水平弹性扩展,通过简单地增加新节点即可实现 TiDB 的水平扩展,按需扩展吞吐或存储,轻松应对高并发、海量数据场景。分布式事务,TiDB 100% 支持标准的 ACID 事务。真正金融级高可用,相比于传统主从(M-S)复制方案,基于 Raft 的多数派选举协议可以提供金融级的 100% 数据强一致性保证,且在不丢失大多数副本的前提下,可以实现故障的自动恢复(auto-failover),无需人工介入。
TiDB 的架构及原理在官网(https://pingcap.com/)里有详细介绍,这里不再赘述。
图 1 TiDB 基础架构图
2.2 TiDB带来的一些惊喜
在TiDB里,完全不用在担心主库的容量问题;
在TiDB里,原生支持OnlineDDL,不用再使用第三方工具引发的其他问题;
在TiDB里,加字段、改字段的操作,秒级完成,不需要在rebuildtable;
在TiDB里,不用再担心主从延迟,引发的一些列不一致相关问题;
在TiDB里,提供了非常详细的监控指标,以及其他生态自动化工具
……
2.3 性能基准测试
硬件配置
| 服务类型 | 主题类型 | 实例数 |
| PD | BMI5(96核/ 384GB/7T NvmeSSD) | 3 |
| TiKV | BMI5(96核/ 384GB/7T NvmeSSD) | 6 |
| TiDB | BMI5(96核/ 384GB/7T NvmeSSD) | 6 |
| Sysbench | BMI5(96核/ 384GB/7T NvmeSSD) | 1 |
软件版本
| 服务类型 | 软件版本 |
| PD | 3.0.18 |
| TiKV | 3.0.18 |
| TiDB | 3.0.18 |
| Sysbench | 3.0.18 |
写入测试
| 线程数 | QPS | 95%latency (ms) |
| 16 | 7705 | 2.81 |
| 32 | 13338 | 3.82 |
| 64 | 21641 | 5.18 |
| 128 | 33155 | 7.84 |
| 256 | 44574 | 12.08 |
| 512 | 58604 | 17.32 |
| 768 | 67901 | 22.28 |
| 1024 | 75028 | 26.68 |
| 1536 | 86010 | 34.33 |
| 2048 | 92380 | 44.98 |
| 2500 | 96671 | 54.8 |
OLTP读写测试
| 线程数 | QPS | 95%latency (ms) |
| 16 | 18000 | 22 |
| 32 | 35600 | 23.1 |
| 64 | 60648 | 26.68 |
| 128 | 92318 | 33.12 |
| 256 | 113686 | 55.82 |
| 512 | 138616 | 94.1 |
| 768 | 164364 | 134.9 |
| 1024 | 190981 | 167.44 |
| 1536 | 223237 | 204.11 |
| 2048 | 262098 | 231.53 |
| 2500 | 276107 | 272.27 |
只读测试
| 线程数 | QPS | 95%latency (ms) |
| 16 | 24235.51 | 15.27 |
| 32 | 45483.64 | 16.71 |
| 64 | 80193.6 | 17.95 |
| 128 | 123851.61 | 20.37 |
| 256 | 144999.89 | 34.3 |
| 512 | 174424.94 | 58.92 |
| 768 | 183365.72 | 86 |
| 1024 | 200460.98 | 108.68 |
| 1536 | 236120.82 | 153.02 |
| 2048 | 264444.73 | 204.11 |
| 2500 | 285103.48 | 253.35 |
三、在TiDB上遭遇的问题及解决
引入TiDB后,我们也遭遇到了一些问题,本节介绍一些重点的问题及对应的解决方式。
3.1 TiDB集群整体平均耗时较高,并且Raftstore线程CPU跑满(200%)
在海量数据和有限的资源场景下,单TiKV承载了较多的Region,在Region通讯上Raftstore Thread有较大的资源开销,在2.x版本线程数固定为2,造成了相关的性能瓶颈。
TiDB社区非常活跃,PingCAP团队对于Bug的修复和新版本的性能优化,有较高的迭代效率。
我们对集群做了一次从2.1到3.0的版本升级,来解决部分问题,3.0GA相关的特性:
稳定性方面,显著提升了大规模集群的稳定性,集群支持 150+ 存储节点,300+TB 存储容量长期稳定运行。易用性方面有显著的提升,降低用户运维成本,例如:标准化慢查询日志,制定日志文件输出规范,新增 EXPLAIN ANALYZE,SQL Trace 功能方便排查问题等。性能方面,与 2.1 相比,TPC-C 性能提升约4.5 倍,Sysbench 性能提升约 1.5 倍。因支持 View,TPC-H 50G Q15 可正常运行。新功能方面增加了窗口函数、视图(实验特性)、分区表、插件系统、悲观锁(实验特性)、SQL Plan Management 等特性。
优化收益非常可观,999分位平均耗时降低5倍以上,达到400-500ms。
3.2 执行计划异常导致TiDB集群负载高,伴随平均响应耗时升高
我们知道,数据库中的统计信息,在不同程度上描述了表中数据的分布情况,执行计划通过统计信息获取符合查询条件的数据大小(行数),来指导执行计划的生成。
在MySQL中,我们遇到过因为执行计划不符合预期,导致选择错误索引,引发慢查询的现象。通常通过添加Force index来指定索引,或重新生成统计信息来解决问题。
在TiDB中,同样存在该类问题,但TiDB的表数据量通常非常巨大在百亿级,一旦发生选择错误索引的情况,将全表扫描所有数据。加上业务的并发请求,这种情况对集群无疑是致命的。严重情况直接导致整个集群不可用。
为了规避该类现象的发生,我们需要尽可能保证统计信息的正确性,提高表的Analyze频率。
自动更新
在发生增加,删除以及修改语句时,TiDB 会自动更新表的总行数以及修改的行数。这些信息会定期持久化下来,更新的周期是 20 * stats-lease,stats-lease 的默认值是 3s,如果将其指定为 0,那么将不会自动更新。
和统计信息自动更新相关的三个系统变量如下:
系统变量名 | 默认值 | 功能 |
| 0.5 | 自动更新阈值 |
|
| 一天中能够进行自动更新的开始时间 |
|
| 一天中能够进行自动更新的结束时间 |
当某个表 tbl 的修改行数与总行数的比值大于 tidb_auto_analyze_ratio,并且当前时间在 tidb_auto_analyze_start_time 和 tidb_auto_analyze_end_time 之间时,TiDB 会在后台执行 ANALYZE TABLE tbl 语句自动更新这个表的统计信息。
表的健康度信息
通过SHOW STATS_HEALTHY可以查看表的统计信息健康度,并粗略估计表上统计信息的准确度。当modify_count>=row_count时,健康度为 0;当modify_count 优化收益 通过TiDB内置自动更新,和辅助监控程序,尽量保证表的健康度在85分以上。 同时调整tidb_build_stats_concurrency(ANALYZE并发度)降低在 ANALYZE过程中对集群产生的压力。优化后至今未出现该类现象。 3.3 读写冲突导致的TiDB集群响应耗时升高 在优化平均耗时过程中,发现写入耗时比较大(INSERT、UPDATE),进一步定位到集群内部发生较多的读写冲突、写写冲突。 首先了解TiDB的乐观锁模型,TiDB中事务使用两阶段提交,分为 Prewrite 和 Commit 两个阶段,示意图如下: 图 2 TiDB 乐观锁模型 相关细节本节不再赘述,详情可阅读Percolator和TiDB事务算法。 (https://pingcap.com/blog-cn/percolator-and-txn) 我们知道 txnLock代表写写锁,txnLockFast代表读写冲突。结合监控锁信息、分析TiDB日志,定位到冲突大多来自oms_waybill_tidb、fvp_scan_gun表的写入和更新操作。 对同条订单记录并发写入和修改,结合乐观锁模式的二阶段提交和锁冲突重试,是导致耗时升高的根本原因,此时我们的优化手段基本有3个: 1.TiDB锁冲突预检 a) 如果发现 TiDB 实例本身就存在写写冲突,那么第一个写入发出后,后面的写入已经清楚地知道自己冲突了,无需再往下层 TiKV 发送请求去检测冲突 b) 但TiDB在集群拓扑中是多点无状态,各进程之间不通讯,经测试优化效果不明显。 2.尝试悲观事务锁模型 a) 悲观事务锁性能上效率更低 b) 尝试效果并不明显 3.同订单记录操作串行化 a) 引入Redis分布式锁,但引入新的组件增加了系统的复杂性,并且有一定的研发成本; b)(选用)业务异步写入场景,使用消息队列串行化请求,将相同读写分配到一个Kafka的partition,规避同一行记录的并发读写 经历了排查分析、反馈业务、优化应用的几个回合,成功降低了TiDB集群的读写、写写冲突数量,整体平均耗时也有一定的下降,提高了集群整体的稳定性。 四、生态 在运维TiDB过程中,我们自主研发了一些工具来应对日常的运维需求。官方也提供一些列生态工具应对与各种场景。 4.1 DbKiller 自主研发,支持配置相关策略,对满足条件的超时查询,进行Kill操作,用于异常查询的连接杀死,和数据库雪崩无法自愈的场景。 4.2 DbCleaner 自主研发,支持配置相关策略,对配置内的表进行窗口期内的归档处理,兼容MySQL并会检查主从延迟。 4.3 Data Migration DM是一体化的数据同步任务管理平台,支持从 MySQL 或 MariaDB 到TiDB 的全量数据迁移和增量数据同步。使用 DM 工具有利于简化错误处理流程,降低运维成本。 (替代了早期的Syncer,满足大部分数据全量、增量同步需求) 图 3 DM工作流程 4.4 TiDB Lightning TiDB Lightning 有以下两个主要的使用场景:一是大量新数据的快速导入;二是全量备份数据的恢复 支持了多次TiDB迁移和升级方案选用。 图 4 Lightning工作流程 五、优化实践 5.1 热点问题 图 5 TiKV存储过程 如图5所示,TiDB以Region为单位对数据进行切分,每个Region有大小限制(默认96M)。Region 的切分方式是范围切分。每个Region 会有多副本,每一组副本,称为一个 Raft Group。每个 Raft Group 中由 Leader 负责执行这块数据的读 & 写(TiDB 即将支持Follower-Read)。Leader 会自动地被 PD 组件均匀调度在不同的物理节点上,用以均分读写压力。 由于从MySQL迁入到TiDB,并且延续了Schema,仍然使用自增ID作为主键,但在TiDB里这并不适用。 带有AUTO_INCREMENT属性的主键,单调递增的写入到某个Region,写满后再拆分或者写入下一个Region,从而每一个Region都将产生热点效应。 热点规避方式:主键变更,Region预创建 如果表没有主键或者主键不是整数类型,而且用户也不想自己生成一个随机分布的主键 ID 的话,TiDB 内部有一个隐式的 _tidb_rowid 列作为行 ID 要避免由 _tidb_rowid 带来的写入热点问题,可以在建表时,使用 SHARD_ROW_ID_BITS 和 PRE_SPLIT_REGIONS 这两个建表选项SHARD_ROW_ID_BITS 用于将 _tidb_rowid 列生成的行 ID 随机打散。PRE_SPLIT_REGIONS 用于在建完表后预先进行 Split region 5.2 历史数据难归档 TiDB在智域系统的场景中,数据可以保存近3个月,其他历史数据均可以归档处理,即为数据导出和数据删除的操作。 但在每天20亿以上数据写入的场景下,DELETE的清理效率极为低下,并且经几次验证,对集群的稳定性也有一定的影响。 优化方式: 此处计划引入分区表,将订单和时间字段作为Key,Range方式支撑分区表的正常使用。 对于历史数据,直接使用删除分区的方式物理删除,提高删除效率,规避对集群的性能影响。 5.3 数据备份 如今SDS的TiDB集群,整体数据量近14T,一次逻辑全量备份将耗时6天。对于高效备份的需求显然是非常迫切的。 Backup& Restore(简称BR)是 TiDB 分布式备份恢复的命令行工具,在TiDB v3.1以上版本开始支持,支持高效的全量备份和增量备份。该功能相关内容在我们的计划当中。 5.4 集群状态定位难 TiDB虽提供了大量的Dashboard指标可以展示,但在排查各类问题时,还需要很多精力进行分析和定位。在TiDBv4.0版本,引入了TiDB DashBoard组件。通过 TiDB DashBoard 以及 TiDB 的集群的诊断报告,我们可以快速拿到集群的基本信息、负载信息、组件信息、配置信息以及错误信息,这些信息其实已经非常的丰富了,对于我们来讲是非常有效的,可以稳准狠的找到我们的集群的异常 图 6 TiDB Dashboard效果图 六、总结 TiDB作为新生代的高性能分布式数据库,在海量数据存储场景是业内的选择趋势。我们会继续保持社区的关注,完善公司内部TiDB相关的运维建设,在合适的场景下斟酌引入使用。 END


发表评论
暂时没有评论,来抢沙发吧~